数据治理新思路:像追溯DNA一样管理你的数据资产
2025-03-25 18:59 浏览量:98
你有没有遇到过这样的数据困境:一个指标异常,却不知道问题出在哪里;一个任务变更,担心会影响到哪些下游;几百个数据任务盘根错节,想理清楚却无从下手...
这些让数据从业者头疼的问题,都指向了一个关键技术 - 数据血缘。
数据血缘技术:重塑大数据治理的未来
在超大规模数据驱动的时代,一个企业的数据规模可能达到数百PB,日均任务量轻松破万。数据血缘技术正悄然崛起,成为撬动企业数据资产的关键支点。
数据血缘技术革新正全方位重塑企业数据治理格局。传统数据治理模式下,企业面临着数据资产管理混乱、数据质量难以保障、数据资源浪费等痛点。数据血缘技术通过构建全链路数据关系图谱,让企业数据资产管理进入智能化新阶段。
在现代企业运营中,一个看似简单的数据报表背后,往往涉及复杂的数据加工链路。从原始日志采集、数据清洗、特征计算,到最终的指标呈现,动辄几十上百个任务节点相互依赖。任何一个环节出现问题,都可能导致数据质量受损。数据血缘技术正是解决这一复杂性的关键。数据血缘技术核心在于解析与追踪数据流转过程中的依赖关系。
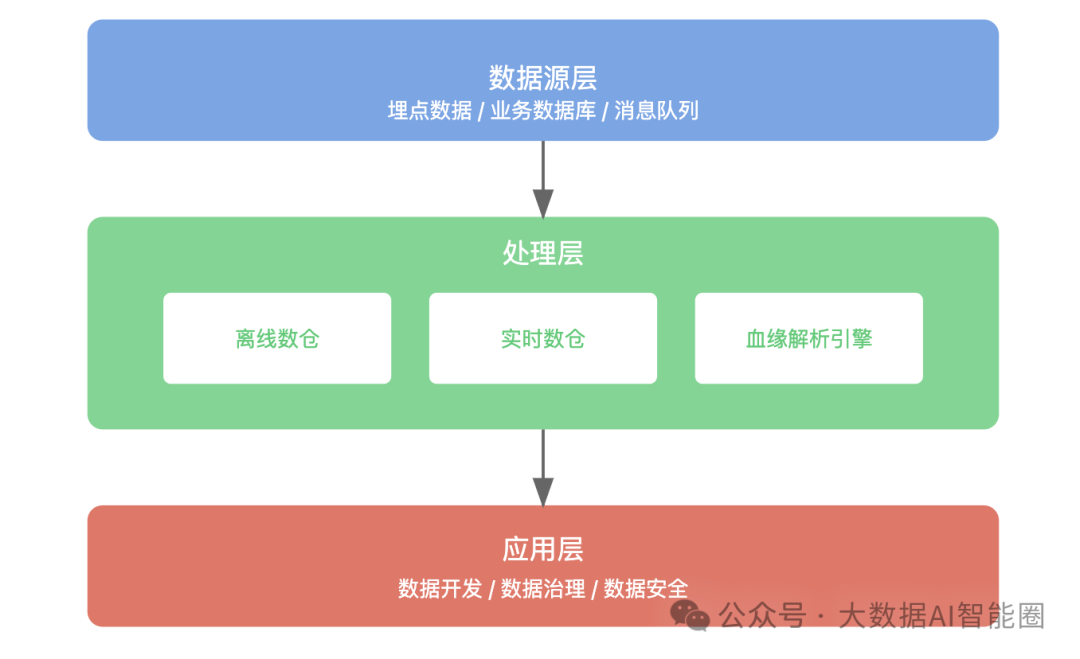
从技术架构看,一个完整的数据血缘系统包含三层:数据源层负责采集各类数据源信息、处理层通过血缘解析引擎分析数据间的关联关系、应用层则基于血缘数据支撑数据开发、治理等场景
在工程实践中,血缘系统面临三大挑战:
全面性
需要覆盖从埋点采集到应用消费的全链路血缘关系。企业级数据体系涉及多种异构数据源,血缘系统要能适配不同类型数据源的解析需求。
准确性
血缘关系解析必须准确无误。任何解析错误都可能误导下游决策。这要求血缘解析引擎具备强大的解析能力,能正确理解各类数据处理逻辑。
实时性
血缘关系需要随数据处理逻辑变化而实时更新。大规模数据体系下每天都有大量任务变更,血缘系统要能快速感知并更新血缘关系。
数据血缘系统:架构设计与关键突破
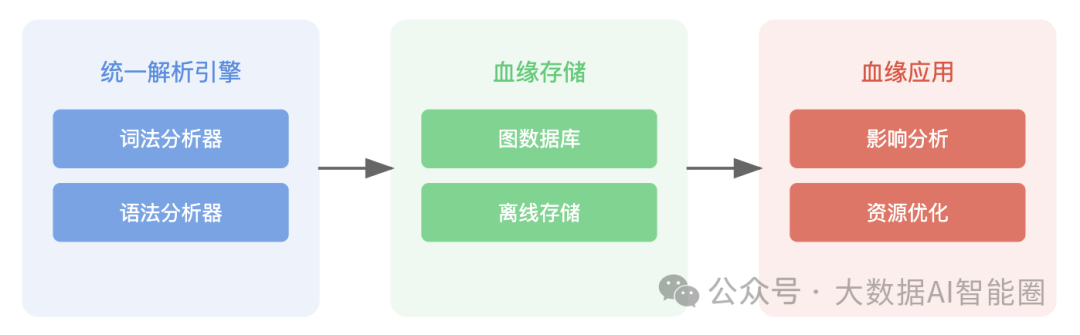
解析引擎作为数据血缘系统的大脑,承担着识别和提取数据间依赖关系的重任。面对SQL、Python、Java等多样化的数据处理代码,解析引擎需要准确理解其中的数据流转逻辑。
业界主流方案采用Antlr和Calcite组合架构。Antlr负责词法和语法解析,将代码转化为抽象语法树;Calcite则专注于SQL优化,提供统一的关系代数模型。这种组合让血缘系统既能处理标准SQL,又能应对复杂的脚本语言。
血缘存储层采用图数据库技术,将数据实体和依赖关系建模为点和边。
考虑到海量血缘数据的存取效率,系统往往会同时维护两套数据模型:一套面向写入优化,一套面向查询优化。这种双模型设计既保证了血缘数据的实时性,又兼顾了查询性能。

在实际应用中,数据血缘技术正在重塑数据开发模式。开发人员通过血缘分析快速定位数据来源,评估代码变更影响范围。血缘系统甚至能基于历史血缘关系,智能推荐最佳数据处理方案,大幅提升开发效率。
数据治理领域,血缘技术让资源优化有了精准抓手。通过分析数据血缘图谱,系统能够识别出重复计算、低价值存储等资源浪费点。运维团队据此进行精准治理,既降低存储成本,又提升计算效率。
数据安全方面,血缘技术为敏感数据保护提供全新思路。系统通过追踪敏感数据的传播路径,及时发现潜在风险,并自动采取脱敏、加密等保护措施。这种基于血缘的主动防护,让数据安全管理更加智能和高效。
数据血缘优化:从评估到提升
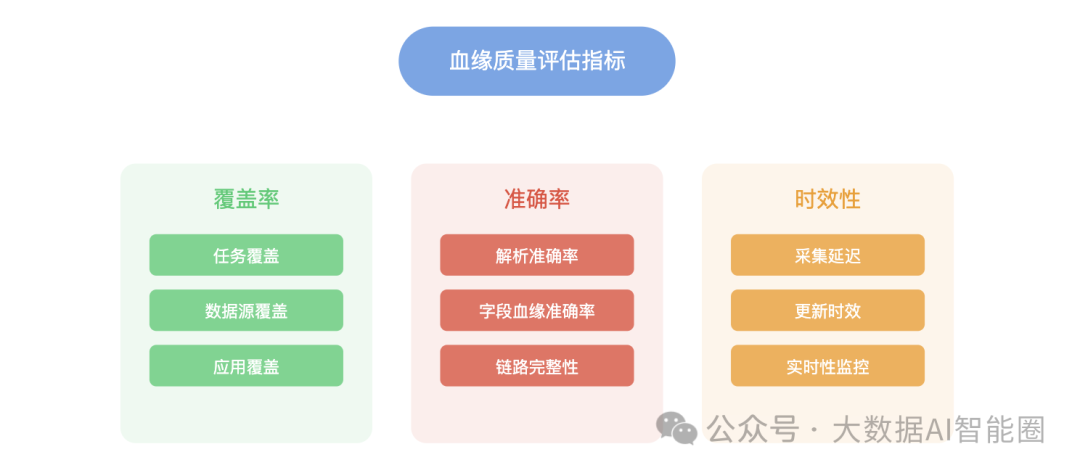
衡量数据血缘系统的质量,需要构建科学的评估体系。业界普遍采用"三率"指标:覆盖率、准确率和时效性。
覆盖率关注血缘系统对数据全链路的把控能力。一个优秀的血缘系统应该覆盖所有关键数据节点,包括数据源采集、任务处理、应用消费等环节。当前头部互联网公司的血缘覆盖率普遍超过95%,有力支撑了数据治理工作。
准确率衡量血缘关系识别的精准度。血缘关系存在表级和字段级两个粒度,字段级血缘解析难度更大。解析准确性直接影响下游应用的可靠性。领先企业通过持续优化解析引擎,将准确率提升至99%以上。
时效性度量血缘信息的新鲜度。在敏捷开发环境下,数据处理逻辑频繁变更,血缘关系需要实时更新。通过流式采集和增量解析等技术,优秀血缘系统能将更新延迟控制在分钟级。
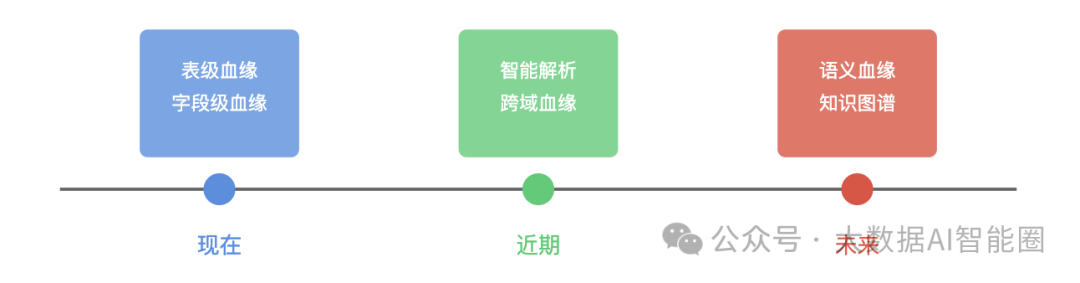
数据血缘技术正在向更智能、更精细的方向演进。
智能解析引擎将借助机器学习技术,提升复杂代码的解析能力。语义级血缘分析将帮助理解数据间的业务关联。知识图谱技术的引入,将让血缘系统具备推理能力,预测数据变更影响。跨域血缘是另一个重要发展方向。
随着企业数据规模扩大,跨数据中心、跨组织的数据协作日益普遍。构建统一的跨域血缘体系,将成为数据治理的新课题。
大数据时代,血缘技术正在成为连接数据资产的桥梁。通过持续创新和实践,血缘技术必将为企业数据治理带来更大价值。
来源(公众号):大数据AI智能圈
- 分享:
热门文章
- 1 AI+大数据 4个关键点:让数据治理变得简单、高效
- 2 AI+大数据 AI与数据的双向奔“赋”
- 3 荣誉奖项 【喜报】龙石数据成功入选苏州市数据创新应用实验室
- 4 数据中台 龙石数据中台V3.5.2升级 | 新增码表转换功能
- 5 荣誉奖项 龙石数据总经理练海荣获评CCSA TC601 2024年度突出贡献专家
- 6 荣誉奖项 智库生态丨龙石数据练海荣、孙晓宁受聘中国信通院政务大数据方向智库专家
- 7 公司动态 龙石数据在DAMA数据管理峰会再次分享数据要素价值运营和第三方数据质量管理
- 8 公司动态 江阴市数据局莅临龙石数据调研
- 9 公司动态 【技能提升】SQL进阶脚本,专业技能再提升,服务再升级
- 10 数据集成 龙石数据集成平台有哪些要点?
