Spark SQL 复杂类型高阶函数详解
2025-02-07 11:00 浏览量:143
spark sql 2.4 新增了高阶函数功能,允许在数组类型中像 scala/python 一样使用高阶函数
背景
复杂类型的数据和真实数据模型相像,但是使用sql操作较为困难,一般需要借助于 explod/collect_list 等方法,或者使用 scala / python 编写UDF,但是对每个方法都要定义并且注册,较为繁琐,其中 python udf 的性能由于需要在 JVM 和 Python 进程中进行序列化,效率更低。
例如现在有这样一种需求,对 t1 表中某个 array 字段 values 的每个元素加1
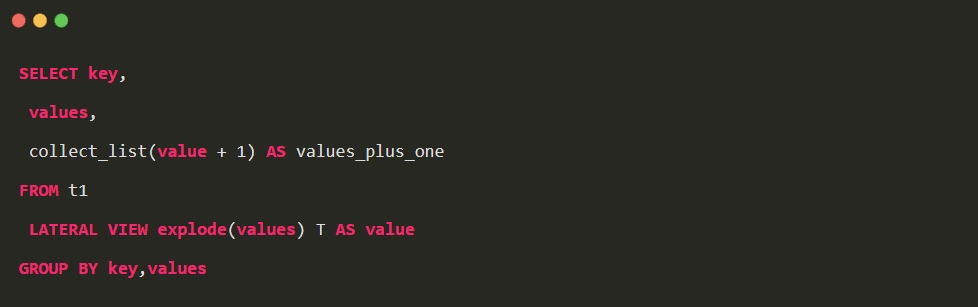
1. 只使用 sql 实现
此类方法会带来 shuffle 的开销,collect_list 也不能保证数据的顺序,同时要保证 group 字段全局唯一,否则结果会出错。
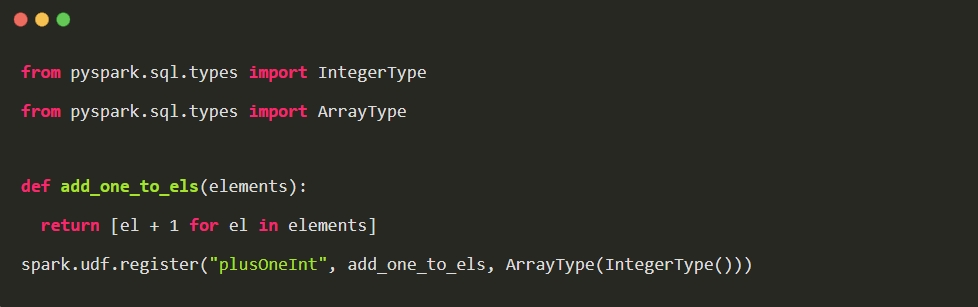
2. 使用 udf 的方式
使用 scala 定义 udf

或者使用 python 定义 udf
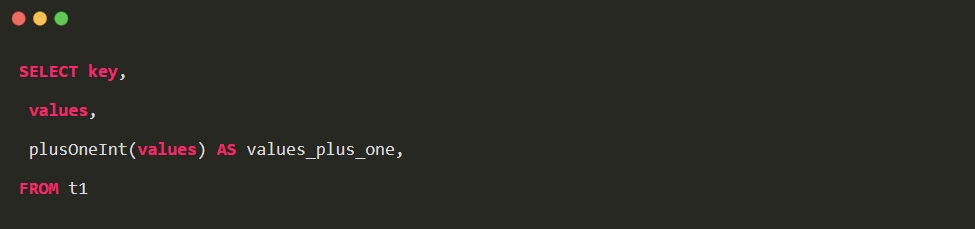
在 sql 中使用 udf
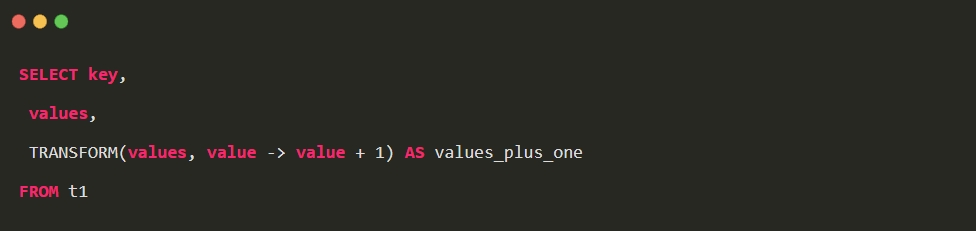
3. 使用高阶函数的方式
三种方式的性能对比图:
使用
Array 高阶函数
目前支持 transform / filter / exists / agregate / zip_with 方法
| id | arr_values | nested_values |
|---|---|---|
| 1 | [1,2,3] | [[1,2],[3,4]] |
1. transform
对一个数组应用 function 产生另一个数组
如果 lambda function 中有两个参数,第一个参数为数组中的元素,第二个参数代表该元素的索引(从0开始)

2. filter
过滤出数组中符合条件的元素

3. exists
数组中的一个或多个元素是否满足条件

4. aggregate
给定初始值,并对数组中所有的元素都应用 function ,如果需要的话还可以加上 finish function

5. zip_with
将两个数组根据 function 合并为一个数组,较短的那个数组会以填充 null 的方式匹配较长的数组

复杂类型内置函数
spark 2.4 增加了大量的内置函数
1.array: array_distinct / array_intersect / array_union / array_except 等
2.map: map_form_arrays / map_from_entries / map_concat
3.array & map : element_at / cardinality
总结
1.spark sql 高阶函数可以避免用户维护大量的 udf ,且提高了性能,增强了复杂类型的处理能力。
2.collect_list / collect_set 返回的结构为 array ,可以直接使用高阶函数进行操作。
来源(公众号):五分钟学大数据
- 分享:
热门文章
- 1 AI+大数据 4个关键点:让数据治理变得简单、高效
- 2 AI+大数据 AI与数据的双向奔“赋”
- 3 荣誉奖项 【喜报】龙石数据成功入选苏州市数据创新应用实验室
- 4 数据中台 龙石数据中台V3.5.2升级 | 新增码表转换功能
- 5 荣誉奖项 龙石数据总经理练海荣获评CCSA TC601 2024年度突出贡献专家
- 6 荣誉奖项 智库生态丨龙石数据练海荣、孙晓宁受聘中国信通院政务大数据方向智库专家
- 7 公司动态 龙石数据在DAMA数据管理峰会再次分享数据要素价值运营和第三方数据质量管理
- 8 公司动态 江阴市数据局莅临龙石数据调研
- 9 公司动态 【技能提升】SQL进阶脚本,专业技能再提升,服务再升级
- 10 数据集成 龙石数据集成平台有哪些要点?
