AI应用:AI赋能元数据管理,让指标应用更为高效
2025-01-15 16:48 浏览量:339
指标平台掀起数智风暴:AI 对话已达 95% 准确率、100% 可解释!
(本文:指标平台 = 元数据管理平台)

安全可靠:是智能数字决策的前提
01 | 应用痛点
元数据管理平台无法满足快速、智能查询需求
随着企业业务规模的迅速扩展和数字化进程的持续深化,越来越多的企业依赖大量精准的数据指标来进行精细化运营管理和辅助战略决策,凸显出构建完善元数据管理平台在企业内部的重要性。但在“元数据管理平台”应用过程中,因管理不统一、指标口径不一致、流程不规范,从而导致了重复建设、资源浪费、沟通成本增加,以及数据结果可信度下降等问题:
1. 指标重复建设与无效开发
指标开发重复:技术团队经常接到相似的指标开发需求,但缺乏统一的指标检索功能,难以快速判断是否已有类似指标,导致重复建设,浪费资源。
缺乏标准化定义:指标定义缺乏统一的标准,不同部门可能基于不同的业务逻辑开发类似指标,结果数据不一致,影响决策的准确性。
2. 业务人员对数据的理解与使用困难
指标选择困难:业务人员在查询指标时,面对数量众多的指标表和字段,不清楚应选择哪个指标,统计口径和适用场景也不明确,增加了使用数据的难度。
理解门槛高:元数据缺乏详细的业务解释或说明,导致非技术用户难以准确理解字段的意义和用途。
3. 元数据维护滞后导致查询错误
表结构变化未及时更新:当数据库的表结构发生变化(如字段新增、删除或调整),元数据没有及时同步更新,导致查询结果不准确,甚至出现错误。
版本混乱与重复沟通:由于元数据不及时更新,技术和业务团队需要反复沟通确认字段含义和统计规则,耗时耗力。
4. 元数据不准确、不一致问题
命名不一致:相同的业务含义在不同表中使用不同的字段名或表名,增加理解难度。
数据冲突:不同表中相同的字段名代表的含义或统计口径不同,数据结果可能存在冲突,用户无法判断取舍。
数据质量缺乏保障:部分元数据可能存在遗漏或记录错误,进一步影响数据使用的准确性。
5. 不同部门之间缺乏统一管理标准
分散管理:各部门独立管理元数据,导致平台缺乏全局视图,用户难以跨部门查询和理解元数据。
标准不统一:不同部门使用不同的元数据管理方式,导致命名规则、统计逻辑等出现分歧,影响跨部门协作效率。
6. 缺乏智能化与便捷性
低效查询:现有元数据管理平台无法支持自然语言查询,用户需要依赖复杂的SQL语句或繁琐的菜单搜索,降低查询效率。
缺少智能推荐:平台无法根据用户需求智能推荐相关指标或字段,用户需要手动筛选,耗费大量时间。
7. 无法支持复杂的血缘关系分析
血缘追踪难:复杂数据血缘关系(如ETL流程、表与表之间的依赖关系)缺乏直观可视化展示,用户难以快速了解数据来源和流转路径。
影响分析滞后:表结构或字段变动后,无法快速识别对下游系统和指标的影响,可能引发系统性错误。
8. 平台可扩展性和用户体验不足
功能单一:现有平台功能无法满足数据查询之外的需求,如数据质量监控、指标健康分析等。
交互体验差:平台界面复杂、搜索不便,用户体验差,进一步限制了元数据的使用频率和价值发挥。
这些痛点清晰地反映了元数据管理平台在实际应用中的不足,同时也为后续平台优化和智能化升级指明了方向。
02 | 方案一:元数据平台优化
如果问题更多在于数据治理、元数据管理策略不完善或平台本身的技术限制,可能需要优化现有元数据管理平台,而不是直接建立知识库。
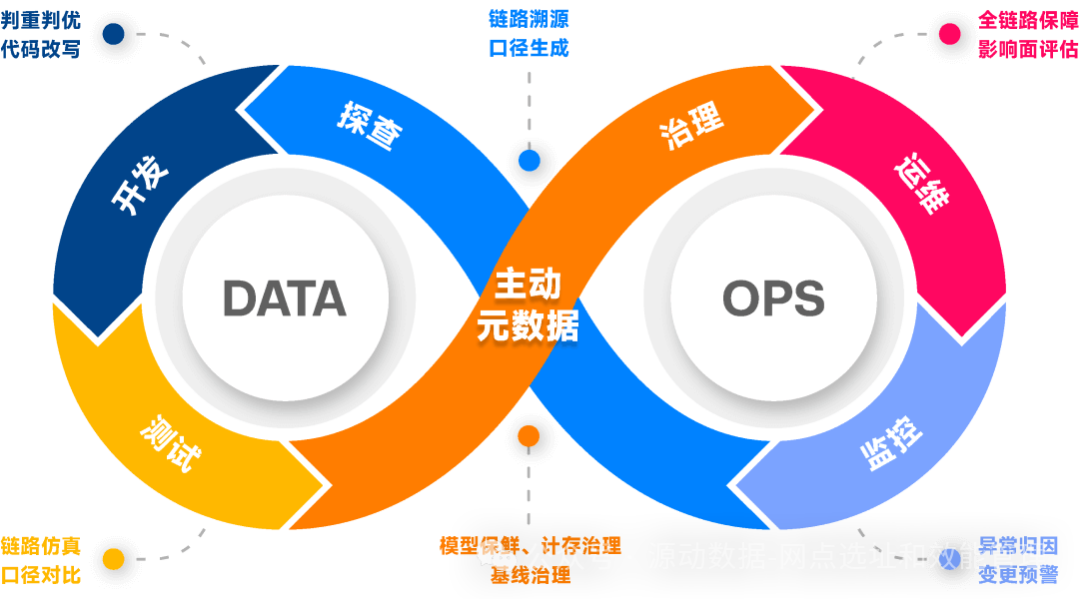
在搭建知识库之前,您可以先评估以下方法:
优化元数据管理平台
增强搜索功能:加入全文搜索、模糊匹配和自动推荐功能。
可视化血缘分析:通过图表清晰展示表间关系和数据流向。
动态更新:对表的访问频率、调用次数等进行定期统计并展示。
数据治理体系完善
冗余表清理:识别并优化低使用率或重复的表。
建立数据分层:划分核心表、辅助表和历史表,减少查找范围。
开发数据搜索引擎
语义搜索:使用自然语言处理(NLP)技术,使用户可以以自然语言查询数据。
智能推荐:根据用户查询历史或业务场景,推荐相关数据表或字段。
03 | 方案二:元数据知识库和智能助手
构建一个元数据管理知识库和智能助手需要以下步骤:
1. 数据准备
元数据收集:
表结构信息:表名、字段名、数据类型、索引、主外键等。
数据血缘:表与表之间的关系,如ETL流程和依赖关系。
表使用统计:访问频率、最近更新时间等。
数据字典:字段含义、业务描述。
清洗与整合:
去重:合并冗余表或字段信息。
标准化:统一元数据格式和命名规则。
2. 技术架构
存储层:使用关系型数据库或NoSQL存储元数据,结合全文搜索引擎(如Elasticsearch)。
逻辑层:建立数据查询引擎,支持多种查询模式(如SQL查询、图数据库查询)。
应用层:
知识库前端界面:方便用户浏览和搜索元数据。
智能助手:通过NLP技术(如ChatGPT、Rasa)实现智能问答和推荐。
3. 功能设计
智能搜索:支持自然语言搜索和复杂查询。
血缘追踪:可视化展示数据血缘关系,支持逐级钻取。
智能推荐:基于用户行为和历史记录,推荐相关表或字段。
访问日志:记录用户查询和访问频率,优化知识库内容。
4. 技术实现
NLP技术:
构建语义搜索引擎,理解用户查询意图。
结合预训练语言模型(如BERT)进行分类和提取。
图数据库:
使用Neo4j或类似工具存储和查询复杂血缘关系。
API层:
提供标准化接口供其他系统调用。
5. 持续维护
定期更新元数据,保持与实际业务一致。
收集用户反馈,优化知识库功能。
来源(公众号): 源动数据-网点选址和效能管理
- 分享:
热门文章
- 1 AI+大数据 4个关键点:让数据治理变得简单、高效
- 2 AI+大数据 AI与数据的双向奔“赋”
- 3 荣誉奖项 【喜报】龙石数据成功入选苏州市数据创新应用实验室
- 4 数据中台 龙石数据中台V3.5.2升级 | 新增码表转换功能
- 5 荣誉奖项 龙石数据总经理练海荣获评CCSA TC601 2024年度突出贡献专家
- 6 荣誉奖项 智库生态丨龙石数据练海荣、孙晓宁受聘中国信通院政务大数据方向智库专家
- 7 公司动态 龙石数据在DAMA数据管理峰会再次分享数据要素价值运营和第三方数据质量管理
- 8 公司动态 江阴市数据局莅临龙石数据调研
- 9 公司动态 【技能提升】SQL进阶脚本,专业技能再提升,服务再升级
- 10 数据集成 龙石数据集成平台有哪些要点?
