企业数据治理应该怎么开展?5步搞定!
2023-03-01 16:44 浏览量:516
企业需要一套围绕用户数据设计的数据治理方案,从而沉淀高质量的用户数据资产,为后续开展精细化运营动作提供有力支撑。
考虑到考虑到企业在实际业务开展时,各渠道用户众多,品牌与用户的触点非常丰富,用户旅程千差万别,因此会产生各种各样的用户、设备 ID 标识及对应的行为事件,导致潜在用户和存量用户之间的关联关系断裂,神策数据全域用户关联(ID-Mapping)方案应运而生,主要聚焦以下三点:
(1) 用户 ID 相关数据收集流程标准化
数据收集流程的标准化,确保每条业务线的用户数据质量,保证用户数据标识统一的有效性和持续落地性,且不会被额外业务系统和新用户数据的引入所影响。
(2) 跨业务线用户 ID 关联方案设计
基于企业当前用户数据的现状,输出符合实际业务应用场景的用户 ID 关联方案,实现全域用户标识的「唯一化」。
(3) 历史存量数据的回溯修复
客户数据平台(CDP)涉及大量历史存量数据的接入,当与业务侧完成用户 ID 关联方案的确认后,也需要完成历史数据的清洗和迁移。
企业如何开展有效的数据治理?用户关联方案为此提供五个步骤解决问题:
1、上下游业务系统数据现状盘点
企业的首要任务是理清 CDP 上下游的业务系统的数据情况,以用户为主体梳理数据应用场景,比如业务数据如何收集、用户数据在什么情况下输出、用户触达场景有哪些等。全域用户关联作为 CDP 系统的基础能力支撑,会对上游数据的收集以及下游业务系统造成影响,所以在方案设计之初需要尽可能对上下游相关的数据现状进行盘点。
接下来为大家阐述典型的数据现状盘点流程:
数据源梳理:梳理各业务线涉及到的业务系统
用户主体 ID 梳理:梳理各业务系统中用于标记用户主体和数据相关的 ID,比如设备 ID、企微 ID、Union ID、Open ID、Cookie ID 等
用户属性梳理:梳理各业务系统中用户标识 ID 对应的数据属性,业务 ID 对应的用户业务属性有卡号、身份、微信号、手机号等
识别用户标识数据在源端存储的质量:例如在数据梳理的过程会发现一个手机号对应多个证件号,这时候需要对数据源产生的原因进行分析,找到异常数据产生的原因,如何在用户关联过程中处理
ID 应用场景梳理:梳理围绕 CDP 应用的整个业务流程中,涉及用户 ID 应用的典型场景,举例来说:
数据接入场景:CDP 全域数据接入(SDK 数据收集 + ETL 数据导入)
数据输出场景:CDP 输出用户分群数据由运营平台推送。具体来说,通过用户唯一标识 ID 携带业务属性、微信属性等输出至运营平台进行推送,其中涉及到用户唯一标识 ID 与业务 ID、UnionID 之间的关联
数据分析场景:微信后台数据对齐,按照 UnionID 统计公众号粉丝数,涉及 UnionID 和 OpenID 的关联,且关注公众号是 UnionID 的微信属性
2、全域用户 ID 关联方案设计
输出用户 ID 关联方案的首要步骤是明确各业务线中哪些 ID 参与用户的关联,并确定 ID 的优先级、数量、父节点等信息,定义如下:
ID 优先级:优先级的设定是为了解决当一条数据中有多个 ID,又无法关联时,数据归属的问题。按照设定,数据会归属优先级更高的 ID 所对应的用户
业务唯一 ID:系统中唯一标识一个用户的 ID 类型,其优先级最高。以电商业务为例,用户的登录 ID 由于和用户购物等行为直接产生关联且可以通过很多途径获取到,往往可以作为「业务唯一 ID」来定义
数量:取决于实际业务中一个用户可以拥有单个还是多个该类型的 ID,可以用来校验关联关系是否符合规则
父节点:在一些业务生态中,ID 之间存在着父子关系。父节点的定义可以用于解绑时一并解绑子节点,比如在微信生态中,UnionID 是 OpenID 的父节点,如果要将 Union ID 进行解绑,则附属的所有 OpenID 也将随之被解绑掉
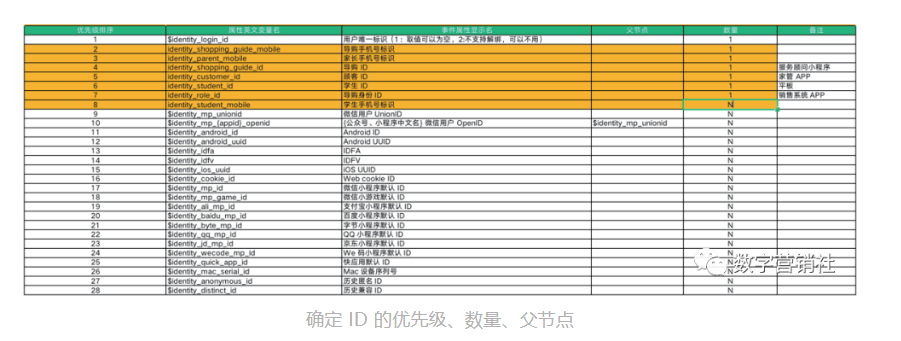
有了完整的 ID 梳理之后,就可以针对性地采用埋点、ETL 等方式,完成用户关联的持续落地了。通俗的来讲,就是明确将哪些业务系统中的哪些数据提取出来再导入 CDP 系统中。业务中每一个事件对应的属性和涉及的 ID 都需要在埋点和 ETL 方案中体现,可以大大减少技术人员的理解成本。
3、用户数据关联的回溯修复
在全域用户关联后,必然会在用户数据中发现历史关联错误的数据。根据新的关联结果,需要对这些错误数据进行解绑并绑定至正确的归属用户,重新完善用户全生命周期画像,从而提升 CDP 的用户数据质量。
举例来说,在用户关联过程中,基于同一个用户的唯一昵称「A」同时对应两个用户「张三 2020 年注册」「李四 2021 年注册」,由此识别为同一个用户,需要对重复关联数据进行合并。在这种情况下,可以参考最早触达用户的时间来完成用户属性的修复:「张三」2020 年注册早于「李四」2021 年注册,因此选择将数据关联至「张三」下。
同理,当历史数据中存在其他类似的「唯一用户 ID」并与当前产生冲突时,需要根据时间先后顺序,将两个「唯一用户 ID」进行合并,完成数据关联的回溯。
4、用户关联属性的冲突处理
企业在进行用户 ID 关联的过程中,会遇到用户关联同类属性冲突的情况,在进行属性合并的过程中,可以遵循以下四个原则:
第一,预置规则:特殊类型属性使用固定的预置规则来处理,比如按照访问时间先后顺序进行属性合并。
第二,缺省规则:默认按照数据生成时间最早的为准,如果没有数据生成时间的相关字段就按照 ID 的优先级来合并。
第三,设置基准规则:设置某个来源的数据为基准,例如相比 CRM 销售人员手动录入的信息数据和业务系统自动获取的订单数据,订单数据的准确性和稳定性显然更高,则选择以业务系统订单数据为基准。
第四,设置首末次规则:最先接入数据的属性为准或者保持最末次的属性。
日常业务中会出现当前用户关联信息错误的情况,比如,用户更换手机导致设备 ID 变更等,这种情况就需要将现有的绑定关系解绑;另一方面我们也发现,曾经认为某个 ID 和用户不相关,后来经过人工等方式确认两者是相关的,这种情况就需要能够在自动关联未成功的情况下,以手动的方式将一个独立 ID 关联到现有用户上去。
5、全域用户关联数据校验及测试验收
以神策数据的 ID-Mapping 全域用户关联为例,数据校验及测试验收整体可以分为五个部分:
用户关联是否成功
完成全域用户关联的部署之后,首先应检查对应埋点方案的上报逻辑是否生效,比如,搜索埋点方案中设计的对应事件是否正常存在。
用户关联全端执行情况
确认事件上报后,可以基于埋点事件确认不同 SDK 类型上报的关联 ID/ 绑定 ID 的总次数。在前后端都调用的情况下,如果不同 SDK 间上报次数相差很多,则需要排查调用时机是否出了问题。
用户关联报错校验
这一步骤旨在确认事件上报的准确性,使用 ID-Mapping 可以在「神策数据治理」→「数据质量」 →「埋点数据查询」中,可以查看是否有大量用户关联的报错,并确认错误数据量、错误分类、错误原因等细节信息。
一般常见的错误分类及解释说明如下:

常见的错误分类以及解释说明
ID 格式校验
检查业务 ID 的格式、长度等是否符合预期。一般来说,业务 ID 都会有相对固定的格式或长度,例如手机号一般都是 11 位,微信生态的 UnionID 和 OpenID 也都有固定的长度,验收人员可以使用 SQL 检查是否有不符合预期的数据。

ID 格式校验示例
ID 关联情况排查
一般可以分为三种情况:
第一,只有登录 ID 的用户:此类用户的特征是业务意义上的登录 ID 有值,其他 ID 均为空。查询只有登录 ID 用户的数量占比,如果发现此类用户占比过高,则可以推断出用户关联可能出现问题,登录用户没有与其他触点的 ID 成功关联上。
第二,只有某个特定触点相关 ID 的用户:例如只有微信生态 UnionID 或 OpenID 的用户,其他业务 ID 均为空。如果此类用户占比过高,则表示该触点可能没有与其他触点打通。
第三,只有设备 ID 的用户:例如发现用户表中存在大量只用 Android_id 的用户,则表明对应 Android 的用户关联可能没有做。
从业务逻辑上来说,一个用户肯定是先有 xxx ID 再有 yyy ID,对此类用户关联情况进行排查时,可以进行 SQL 查询,如果查询结果不符合业务逻辑,则需要进一步排查是否确实没有实现关联的用户,还是用户关联出现了问题,或者 ID 数据本身存在错误。
来源:数字营销社
- 分享:
热门文章
- 1 AI+大数据 4个关键点:让数据治理变得简单、高效
- 2 AI+大数据 AI与数据的双向奔“赋”
- 3 荣誉奖项 【喜报】龙石数据成功入选苏州市数据创新应用实验室
- 4 数据中台 龙石数据中台V3.5.2升级 | 新增码表转换功能
- 5 荣誉奖项 龙石数据总经理练海荣获评CCSA TC601 2024年度突出贡献专家
- 6 荣誉奖项 智库生态丨龙石数据练海荣、孙晓宁受聘中国信通院政务大数据方向智库专家
- 7 公司动态 龙石数据在DAMA数据管理峰会再次分享数据要素价值运营和第三方数据质量管理
- 8 公司动态 江阴市数据局莅临龙石数据调研
- 9 公司动态 【技能提升】SQL进阶脚本,专业技能再提升,服务再升级
- 10 数据集成 龙石数据集成平台有哪些要点?
