数据治理之需求层次
2023-02-08 08:50 浏览量:624
一、什么是数据治理
国际数据管理协会(DAMA)给出的定义:数据治理是对数据资产管理行使权力和控制的活动集合。
国际数据治理研究所(DGI)给出的定义:数据治理是一个通过一系列信息相关的过程来实现决策权和职责分工的系统,这些过程按照达成共识的模型来执行,该模型描述了谁(Who)能根据什么信息,在什么时间(When)和情况(Where)下,用什么方法(How),采取什么行动(What)。
IBM给出的定义:数据治理通过不同的策略和标准提高组织数据的可用性、质量和安全性。这些流程确定数据所有者、数据安全措施和数据的预期用途。总体而言,数据治理的目标是维护安全且易于访问的高质量数据,以获取更深入的业务洞察。
不同的企业和机构对数据治理有不同的理解和目标。通过我的理解和查阅,数据治理比较通用的目标是:
通过一系列技术等手段提升企业数据质量、稳定性和安全性
通过数据标准和数据资产的建立,提高数据资产使用效率,降低数据使用成本
通过数据挖掘,提升数据的价值,提高企业核心竞争力和影响力,实现商业价值
针对上面的目标,参考马斯洛需求的分层,我也将数据治理分成了5层。
二、数据治理的需求分层
马斯洛需求的五个层次分别是:生理需求、安全需求、社交需求、尊重需求、自我实现需求
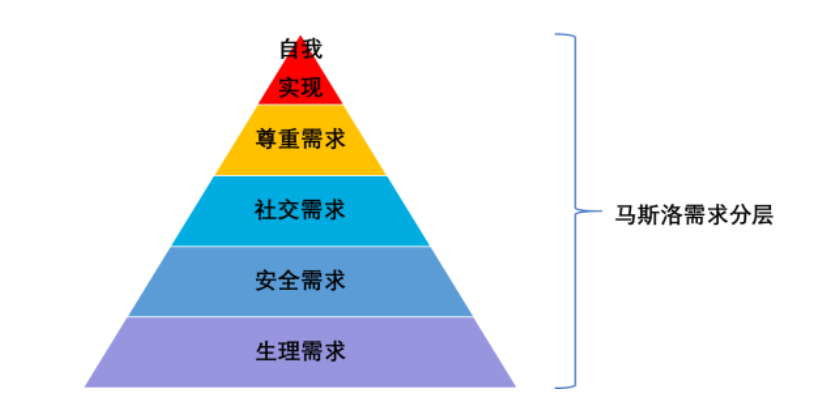
按照马斯洛需求分层的模式我们可以将数据治理分成以下五个层次,分别是:稳定需求、安全需求、易用需求、质量需求、成本价值需求
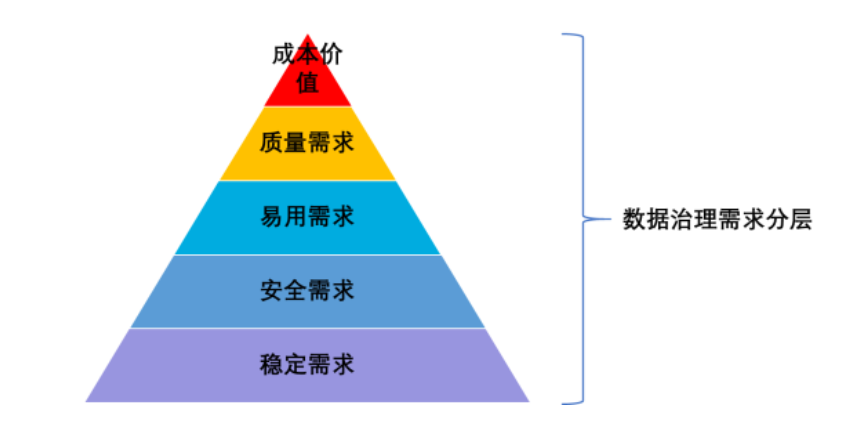
模型越往上带来的价值越高,越往下越是基础的要求。但是没有基础需求层的支持就谈不上上层的需求。
三、稳定需求
数据的稳定性需求是指数据能够稳定产出,并且产出及时。就相当于马斯洛的第一层生理需求,解决吃饱饭(稳定产生数据)的问题。
这里对于数据稳定,我们将获取数据的及时性也归纳为稳定,那么主要分为3个维度,2个指标:
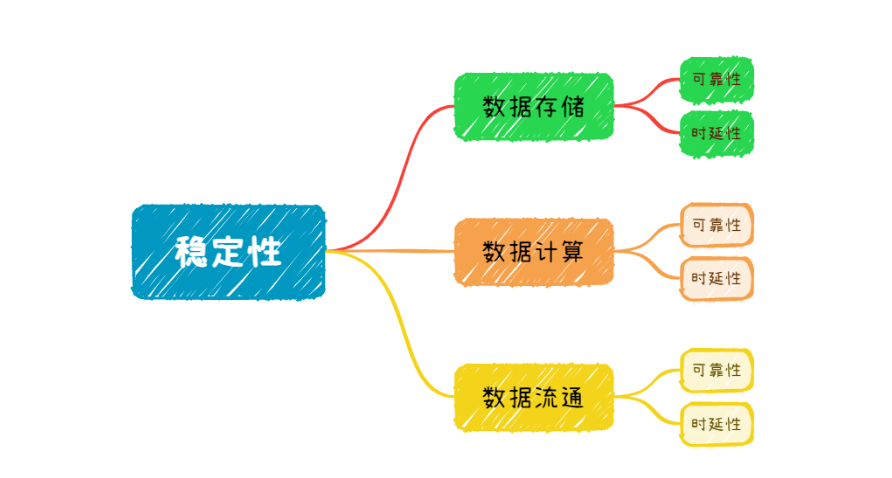
可靠性:
在高可靠性(也称为可用性,英文描述为HA,High Available)里有个衡量其可靠性的标准——X个9,这个X是代表数字,X个9表示在系统1年时间的使用过程中,系统可以正常使用时间与总时间(1年)之比。
3个9:(1-99.9%)*365*24=8.76小时
4个9:(1-99.99%)*365*24=0.876小时=52.6分钟
5个9:(1-99.999%)*365*24*60=5.26分钟
由于数据数据计算往往不是供用户直接使用的在线系统,有的业务中经常用数据计算任务出现问题的次数来衡量数据的可靠性。
时延性
在大数据中我们经常将(交易日期 Transaction Date 简称 T,数据产生的日期)作为基准,然后通过它来描述数据行为产生到数据结果呈现的延迟。它们是:
T + 0:当天就能看到当天发生的数据,如果是及时的就是实时数据
T + 1:当天产生的数据,在第二天才可以查询
T+ 2,T+3 ... :当天产生的数据,在第2,3...天才可以查询
此外 T 可以指代当周、当月、当年,如当 T+1 的月数据,是指当月产生的数据,在次月才能看到数据,一般适用于月度统计。
在准实时数据处理中也可以用H+0,H+1的方式来反馈数据处理的时延。
四、安全需求
数据安全需求,是指数据权限管理、敏感数据保护、合规要求。就相当于马斯洛的第二层安全需求,解决环境安全(数据安全合规)的问题。
数据安全包括两个方面第一就是数据不被泄露窃取,第二个就是数据合法合规。随着欧洲联盟《通用数据保护条例》(General Data Protection Regulation,简称GDPR)的颁布和《国内数据安全法》,《个人信息保护法》的实施,数据安全越来越重要。
数据权限
近年来,随着互联网的快速发展,数据泄漏屡见不鲜,基本上每年都会有数据或者账号的泄露的事件。如果数据安全都不能保证,那就谈不上数据治理。通常我们可以从下面三方面去做好数据的权限控制和隔离:
计算存储资源的多租户数据隔离
系统的多账号角色权限数据隔离
内外网以及系统之间的数据隔离
数据合规
数据合规是指数据存储和使用符合相关法规和规范的要求。按照法规、公司制度、监管或行业标准对数据一般有以下要求:
存档保留的时间
数据脱敏处理
对于像身份证、手机号、住址、籍贯等个人隐私敏感数据以及财务等企业敏感数据,必须要做好相应的脱敏处理,保证数据不被泄露。方法通常有遮盖处理、静态加密算法加密、动态加密算法加密。
合规的获取和使用用户数据
五、易用需求
数据易用需求,是指数据在共享使用中,易于查询,理解,规范。就相当于马斯洛的第三层社交需求,解决交流分享(数据易查询使用)的问题。这个层主要解决的范畴为:
数据查询
对于这块,往往是通过搭建一套BI,OLAP自主系统等手段来提升用户的使用查询数据的体验。技术手段比如采用开源的OLAP引擎:Kylin、Druid、ClickHouse、Doris、StarRocks,开源的数据可视化组件:Superset、Grafana、Davinci
常用指标有:TP90, TP95, TP99查询返回时间,即 9X% 的数据都满足某一条件;
QPS:(Queries Per Second),每秒查询率。
数据标准
业务标准规范。数据统计标准,例如CTR,ROI如何计算;数据中分类的统一规范。
技术标准规范。数据的类型、长度、格式、编码、命名规则等。
管理标准规范。数据访问的标准流程,数据的删除,接入规范
数据模型
数据模型的复用性。复用性低,说明模型设计的不太好,新需求不能基于模型开展,提高了开发维护成本。
数据模型的耦合性。耦合度过高会给数据的运维、治理带来很多影响,在数据下线、变更、治理过程中不得不考虑到依赖。
数据模型的稳定性。稳定性差,经常变动说明设计脱离业务,缺乏标准或者业务覆盖度不够。
解决好上面三方面的需求,数据易用性基本上就可以达到用户需求,数据治理成效也可以用前端页面给用户体现出来。
六、 质量需求
数据易用需求,是指数据在准确性、完整性、一致性、有效性。就相当于马斯洛的第四层尊重需求,解决受人尊重(解决数据质量就会被使用者尊重)的问题。
数据质量需求主要依靠数据监控和数据调度配合完成才能提高数据质量,当然人工的参与和流程也需要规范。
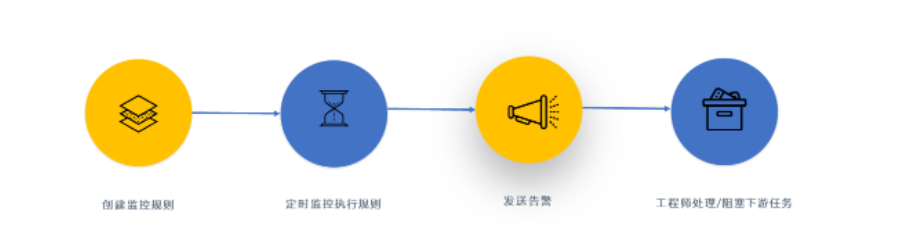
数据准确性监控。主要监控数据接入是否符合标准,数据产生到计算结果过程中数据是否出错,不一致。
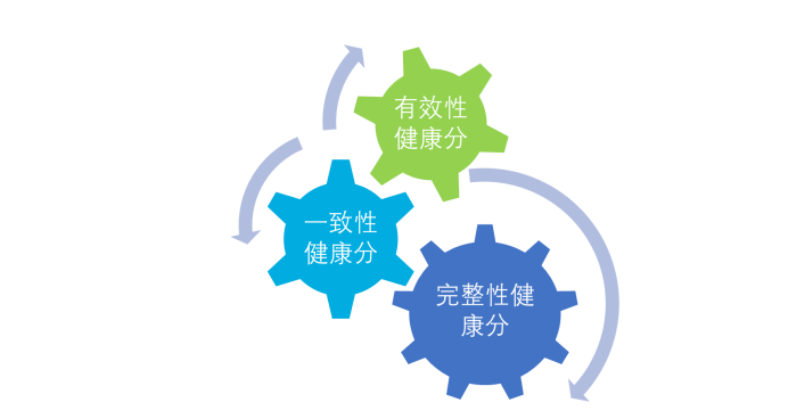
数据完整性监控。
数据一致性监控。监测两种数据渠道数据结果是否一致。
数据有效性监控
通过监测我们可以产生数据质量质量的数据,我们可以通过一些算法形成数据质量报告,来定期评估数据质量的提升。
七、 成本价值需求
数据成本价值需求,是指数据生产的经济性,数据应用创造的价值。就相当于马斯洛的第五层自我实现需求,解决花钱赚钱(解决数据产生效益,完成自我实现)的问题。
这一层次的需求主要其实就是通过降低成本增加收益。我认为做到以下几点是数据质量在这块关注的重点:
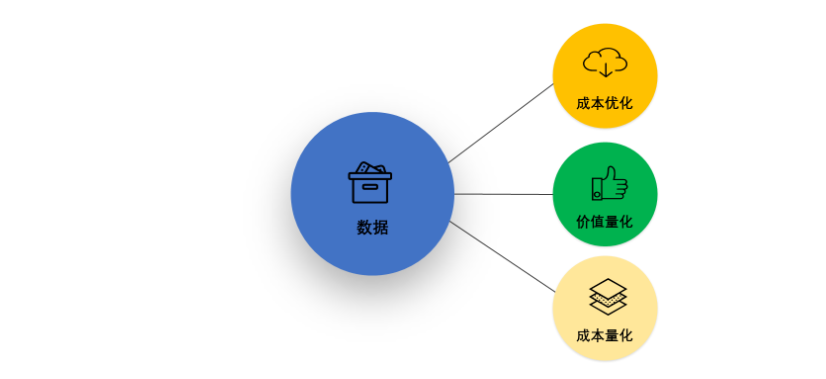
成本量化
数据血缘,元数据管理等手段,理清每个表数据的成本。通过日志分析来可视化每个大数据处理任务Job的费用。
价值量化
数据治理到底重不重要,能带来什么价值,一直是困扰企业数据治理问题,也会经常被企业领导和业务部门质疑。如果能有够将数据治理带来的成功量化那势必会打消大家的疑虑。例如通过数据治理业务部门节约了多少成本;通过数据质量的提高业务部门的ROI是否得到提高;通过数据稳定性安全性的提升,业务系统是否更加稳定和避免了数据泄露损失。
成本优化
通过表热度分析,处理僵尸报表和任务。对数据表进行LTV分析,对于低价值高消耗的数据计算任务,进行降级处理,例如降低计算频次,排到计算资源空闲的时间处理,存储在成本较低的介质上。对于高价值高消耗的任务,评估成本改造方案。
八、总结
数据治理几个需求分层之间是相互依赖不断迭代的,越往上层越接近业务,也越容易体现数据治理带来的成功。要想数据治理取得成功,除了技术工具,我们还应该关注流程规范和组织保障。
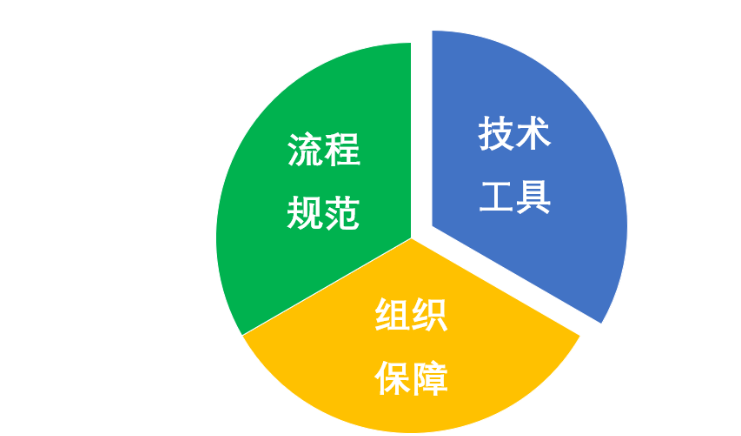
组织保障
组织统一规划数据治理目标,固定的专业组织、充分赋权,有利于数据治理实施的整体推进;一套行之有效的制度,更容易让数据治理,数据规范落地执行。
流程规范
这个其实就是指在数据治理中制定的数据接入输出等相关流程,建立的数据标准。有了流程规范才能知道数据治理的方向和细则,避免数据使用和提供方盲目抓虾。
技术工具
技术工具平台是保障数据成果转化的关键,没有工具平台数据治理可能最后只是设想和空谈。一组优秀的平台工具可以保障数据治理规划和流程的完整落地,从而产生价值收益。
在数据治理过程中我们应该结合需求层次制定具体方案,通过评估收益来决策数据治理的投入。
来源:迪答数据
作者:早起的码农
- 分享:
热门文章
- 1 AI+大数据 4个关键点:让数据治理变得简单、高效
- 2 AI+大数据 AI与数据的双向奔“赋”
- 3 荣誉奖项 【喜报】龙石数据成功入选苏州市数据创新应用实验室
- 4 数据中台 龙石数据中台V3.5.2升级 | 新增码表转换功能
- 5 荣誉奖项 龙石数据总经理练海荣获评CCSA TC601 2024年度突出贡献专家
- 6 荣誉奖项 智库生态丨龙石数据练海荣、孙晓宁受聘中国信通院政务大数据方向智库专家
- 7 公司动态 龙石数据在DAMA数据管理峰会再次分享数据要素价值运营和第三方数据质量管理
- 8 公司动态 江阴市数据局莅临龙石数据调研
- 9 公司动态 【技能提升】SQL进阶脚本,专业技能再提升,服务再升级
- 10 数据集成 龙石数据集成平台有哪些要点?
