谈谈数据编织与数据网格、数据虚拟化、数据湖的区别
2023-02-03 21:33 浏览量:859
什么是数据虚拟化
根据Gartner的定义,虚拟化是IT资源的抽象,它向资源用户掩盖了它们的物理性质和边界。将定义扩展到数据,数据虚拟化是数据集成的概念,它通过消除数据孤岛和连接所有数据资产来创建虚拟抽象层。它为数据生态系统中的不同应用程序提供了一个通用层。
DAMA(国际数据管理协会)是这样定义数据虚拟化的:
数据虚拟化使分布式数据库和多个异构数据存储能够作为单个数据库进行访问和查看。因此,数据虚拟化服务器不是使用转换引擎对数据进行物理ETL,而是虚拟地执行数据提取、转换和集成。
数据虚拟化的目标是构建所有数据的单一视图,无论来源或格式如何,而无需物理复制或移动该数据。
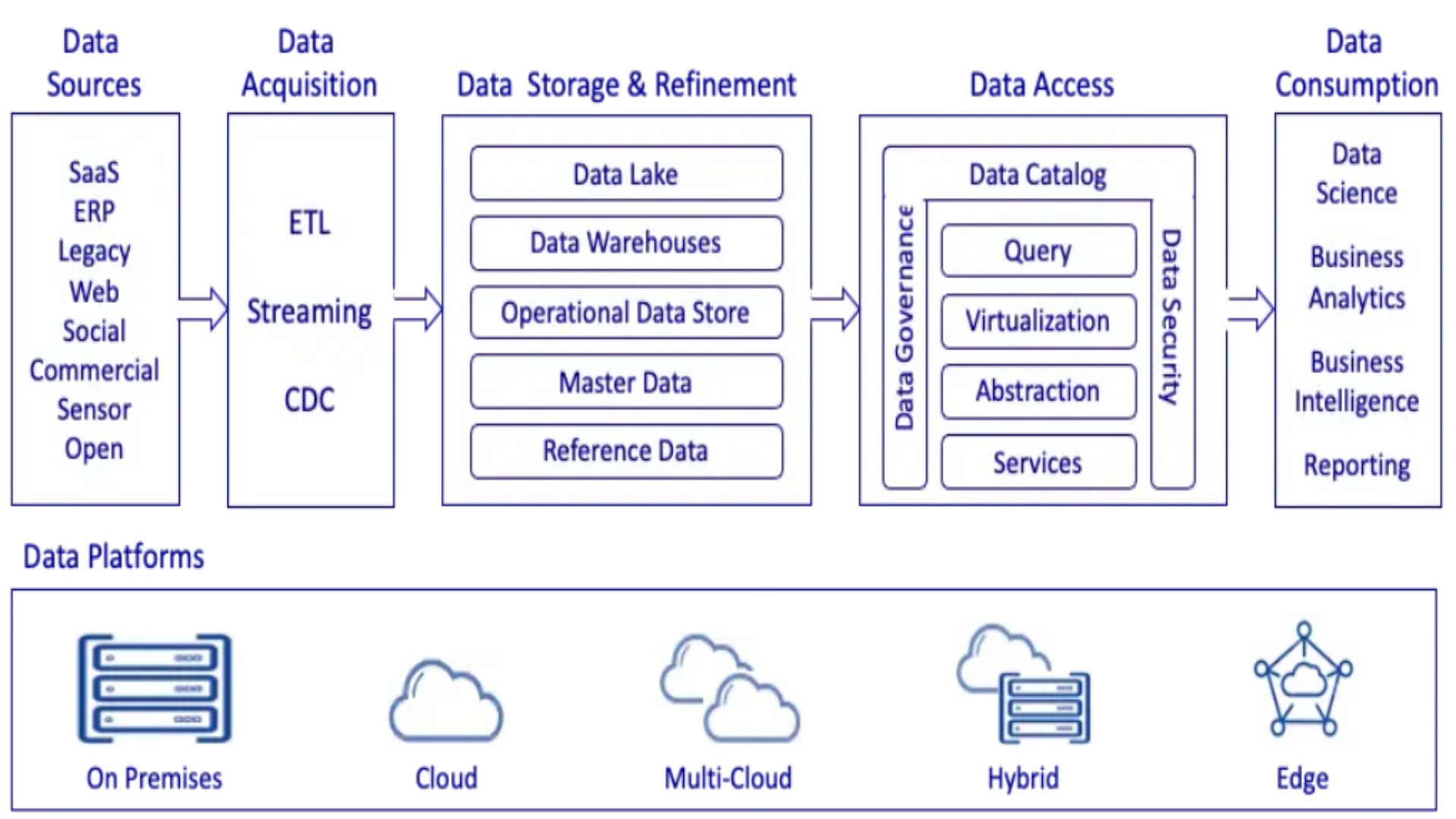
什么是数据湖
数据湖是存储从各种源系统(事务数据库、传感器设备、SaaS应用程序、文件共享系统等)收集的信息副本的存储库,以其本机格式供ML解决方案处理、备份和归档、大数据分析等。
首先,从各种来源获取的信息进入着陆区,在那里它暂时保持原样。当一家公司建立了持续摄取、提取、转换和加载(ETL)和变更数据捕获(CDC)能力时,多类型信息可以在创建后立即进入数据湖。一旦数据进入湖中,每组数据都会被分配一个唯一的指示符或索引,以及一个元数据标签,以加快查询速度并帮助用户快速查找请求的数据。之后,数据可能会经过清洗、重复数据删除、重新格式化、丰富等操作,然后移至可信区域进行永久存储。当信息准备好供下游用户使用时,它可能会直接进入报告和仪表板,或者经过另一轮ETL并存储在数据仓库中以供进一步处理。

什么是数据编织
数据编织是一种设计方法,它意味着将数据生态系统的复杂组件组合到一个统一的平台中,以提供完整和有凝聚力的数据管理。与数据湖不同,数据编织不需要将数据移动到集中位置,而是依赖强大的数据治理策略来实现数据管理统一。
为了促进跨不同系统访问信息、管理其生命周期并将其公开给最终用户,DataFabric架构支持:
数据整合
任何信息,无论其类型、数量和位置如何,都可以被用户整合和访问,因为数据编织允许利用数据虚拟化层来整合数据,而无需移动数据和创建大量副本。除此之外,为了保证数据的完整性,DataFabric可以采用ETL、CDC、流处理等。
智能数据目录
数据目录是企业拥有的所有数据的详细清单。随着数据编织统一了大量信息,数据目录维护元数据以帮助数据消费者(包括分析师、数据库工程师、科学家、业务用户等)查找和理解数据、跟踪其沿袭、评估和管理数据等等.
动态元数据管理
数据编织通常采用人工智能功能,帮助自动检测、分析、收集和激活元数据。
数据治理
数据治理确保数据消费者在各自的策略(访问策略、屏蔽策略、数据质量策略等)的帮助下只能访问他们需要的高质量信息,这些策略由于元数据激活功能而自动执行。

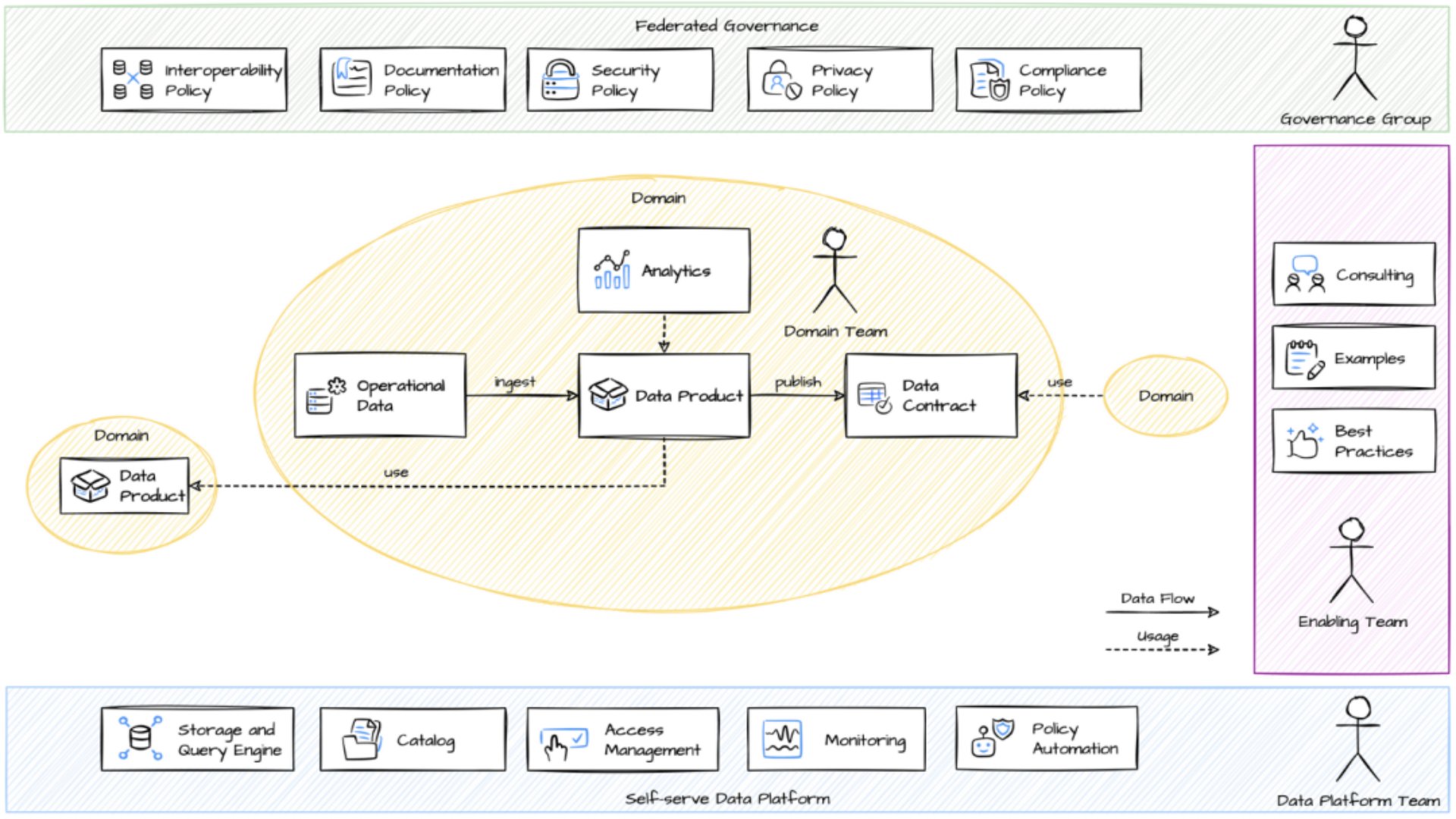
什么是数据网格
数据网格是一种分布式数据架构,在集中管理和互操作性标准化下,由共享和协调的自助数据基础设施支持。数据网格模式代表分散的和特定领域的数据所有权,这些数据所有权很容易被发现并可供组织中的每个人使用。
数据网格有几个区别于其他模式的关键特征:
数据所有权:数据网格跨不同域存储数据。此数据由领域专家维护和管理。
数据作为产品:每个数据域都被视为一个产品,用户就是它的客户。
自助数据平台:数据网格提倡建立一个生态系统,支持创建、使用和维护数据产品,而无需专业知识或复杂工具和技术方面的专业知识。
联合计算治理:分散的数据产品可能导致数据孤岛。联合治理方法将与数据相关的规则、定义和过程标准化。
数据网格脱离了集中存储、转换和处理分析数据的概念。相反,它提倡每个业务领域负责托管、准备数据并将其提供给自己的领域和更大的受众。
比较:数据编织与数据虚拟化
数据编制是一种用于现代数据管理的端到端架构。数据结构用于简化数据发现、治理和主动元数据管理。当组织需要一个集中式平台来访问、管理和治理所有数据时,应使用数据结构。数据虚拟化创建了一个数据抽象层来集成所有数据,而无需物理移动数据。当需要快速集成数据时,使用数据虚拟化。数据虚拟化应被视为数据结构架构的核心元素之一。
数据虚拟化改变了数据到达分析师、数据科学家、企业或应用程序手中的方式。它不是将数据物理地移动到云端或本地,而是创建一个抽象层或数据虚拟化层。因此,它连接到不同的数据源、摄取数据、执行 ETL 过程并创建虚拟数据层,从而允许用户实时利用来自多个来源的数据。
Data Virtualization 是支持 Data Fabric 的技术之一。Data Fabric 是一个端到端数据管理架构,其目标或用例不仅仅是在云端或业务分析师手中获取数据,而是处理更广泛的情况,如客户智能或客户 360 度视图或物联网分析。Data Fabric 适用于更大范围的技术堆栈。
比较:数据编织与数据湖
数据湖是数据和数据资产的存储库,而数据编织是提取和利用此类信息的方法。许多专家认为这两个短语是同义词,使用数据编织从存储的数据中提取最大价值是最好的方法。但是,它们之间存在显着差异。
数据湖是未排序或索引的原始形式的数据存储库。数据可能是从简单文件到大型二进制对象的任何内容,例如视频、音频、图像或多媒体文件。提取数据后,会对其进行评估和操作以使其可用。
术语“数据编织”是指一个组织的数据在所有存储和使用场景中使用的系统,它使用同一组协议、流程、组织和安全性。
比较:数据编织与数据网格
尽管数据编织和数据网格这两个术语有时可以互换使用,但它们代表了截然不同的概念。一般来说,数据编织和数据网格的相似之处在于它们都是识别企业如何管理大量存储信息的技术。数据编织方法旨在通过在数据保存的地方构建一个管理层来规范数据。后者与前者的不同之处在于,某些类型的数据管理的各个方面由组织内利用该信息的团队或小组处理。
另一方面,数据编织是一种以技术为中心的架构方法,可解决数据和元数据的难题。相比之下,数据网格更侧重于组织变革,强调人员和程序而不是架构。
作者:晓晓
来源:数据驱动智能
- 分享:
热门文章
- 1 AI+大数据 4个关键点:让数据治理变得简单、高效
- 2 AI+大数据 AI与数据的双向奔“赋”
- 3 荣誉奖项 【喜报】龙石数据成功入选苏州市数据创新应用实验室
- 4 数据中台 龙石数据中台V3.5.2升级 | 新增码表转换功能
- 5 荣誉奖项 龙石数据总经理练海荣获评CCSA TC601 2024年度突出贡献专家
- 6 荣誉奖项 智库生态丨龙石数据练海荣、孙晓宁受聘中国信通院政务大数据方向智库专家
- 7 公司动态 龙石数据在DAMA数据管理峰会再次分享数据要素价值运营和第三方数据质量管理
- 8 公司动态 江阴市数据局莅临龙石数据调研
- 9 公司动态 【技能提升】SQL进阶脚本,专业技能再提升,服务再升级
- 10 数据集成 龙石数据集成平台有哪些要点?
