华为数据治理之公安、人社建模
2022-12-11 17:49 浏览量:779
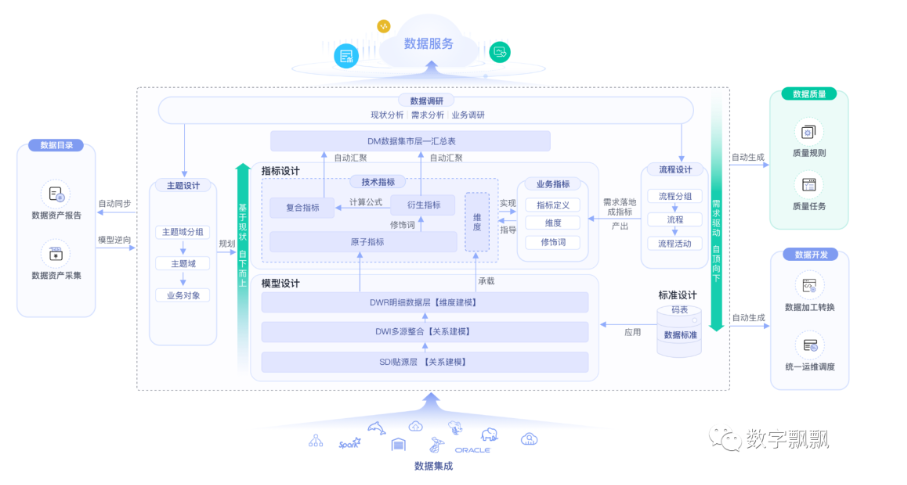
经过这么些年的实践,无论是数字政府,还是智慧城市,这些项目的总体技术架构已经形成共识。首先,建设一个大大的中台,再基于这个中台提供各项应用,一网通办利用中台支持市民办事,一网统管利用中台支撑事件调度,市域治理、城市管理以及平安社区等利用中台支撑研判预警。其次,中台能力也逐渐明确,业务、数据、AI、安全成为标准配置,其中数据平台是整个中台的基础性建设,数据治理建模又是数据平台的基础性工作。
对于数据中台,有制作过一个关于阿里和华为的大数据产品对比的视频,在【华为、阿里的数据治理哪家强】中有对两家公司的数据治理方法做过比较说明,本篇文章以政府公安和人社部门数据为例,用华为方法对其进行建模实践。
首先是SDI层,公安的主要业务领域包括治安、交通、出入境等多个业务领域,按华为的模型设计架构,L1应该是公安领域,L2可进一步细化为治安、交通、出入境等细分领域。L3是业务对象,治安工作的业务对象是人,所以治安领域下可进一步设计L3为人口管理,考虑将从公安归集过来的与人口相关的几个表都纳入进来进行集中管控,因此人口管理下的L4包括诸如流动信息、人口信息、死亡信息、户籍信息和居住证信息等库表,那么这些表中的属性构成了L5,这里不再一一罗列。

其次是DWI层,华为对本层的要求是清洗和整合,其中清洗工作主要由程序脚本来完成,不属于建模,这里不讲。整合工作即包括了3NF规范,又包括了一定的内容融合,考虑到流动信息、人口信息、死亡信息、户籍信息和居住证信息等库表包括了大量的重复信息,可以相互集成并整合到一起,比如以人口信息表为基础,然后合入额外的诸如流动信息、死户信息、户籍信息等即可形成一个更齐全的人口基本信息库表,从而完成整合工作。
第三是DWR层,华为对本层的要求是识别维度,同时保持与DWI层相同的颗粒度。这里作为示例将人口基础信息库表中的行政区划、性别、民族、户口性质等作为维度。这里的颗粒度要求应该辩证地看,可以按华为要求来,但考虑到数仓是一个逐层向上收敛的过程,本层也可以按维度进行收敛,但需要注意,这里的收敛应该是基于业务要求的最小颗粒度。
怎么来理解这个基于业务要求的最小颗粒度?
如果业务要求时间维度需要精细到小时,那么本层在时间维度上就需要收敛到小时,不能收敛到日。对应到例子里面就是至少要收敛到个人,因为人口管理研究的最小业务颗粒度是个人,即身份证号码。此时,这个基于最小业务要求颗粒度整合过的表与维度表形成关联关系,从而完成了维度建模。
第四是DM层,华为对本层的要求是基于场景形成指标表。这里举的应用场景是按区域、性别、民族、学历、户口分析区域人口均衡性,即按上述维度进行分组,对人口数进行统计,其中人口数就是数据指标。这里将维度信息和数据指标全部设计进一个模型当中,对外提供这个模型即可。
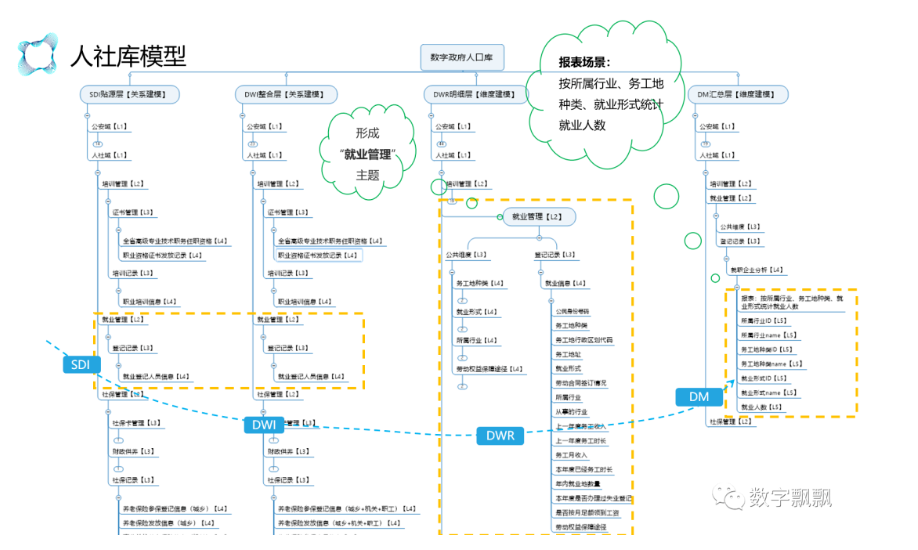
上述是针对公安数据进行的建模,人社数据建模过程也基本相同,首先按照人社业务,进一步细分为培训、就业、社保三个L2细分领域,对于就业管理下的业务对象至少有就业登记L3,将就业登记人员信息库表纳入L4中进行管理,因其为独立表在DWI中无整合要求,但有清洗要求。在DWR中将该表的务工地种类、就业形式、所属行业等作为维度进行管理,在DM层,设置一个应用场景为按所属行业、务工地种类、就业形式统计就业人数,其中就业人数就是数据指标。
根据分析结论看,阿里和华为在建模方面有很多相同之处,不少信息可以是可以相互对应的,比如上面例子中华为模型L1是人社域,可以对应阿里的【业务分类】,华为模型人社L2包括培训、就业和社保,可以对应阿里的【数据域】,华为模型人社L3包括登记记录,可以应对阿里的【业务过程】。
另阿里各层先后经过数据清洗、明细宽表、维度汇总和指标汇总,这种逐层收敛的过程更符合经典数仓要求,这与华为方法中第三层与第二层保持颗粒度一致的说法略有差异,在具体实践时,将两种方法互为辩证与参考使用,会比偏听偏信更合适些。
来源:数字飘飘
- 分享:
热门文章
- 1 AI+大数据 4个关键点:让数据治理变得简单、高效
- 2 AI+大数据 AI与数据的双向奔“赋”
- 3 荣誉奖项 【喜报】龙石数据成功入选苏州市数据创新应用实验室
- 4 数据中台 龙石数据中台V3.5.2升级 | 新增码表转换功能
- 5 荣誉奖项 龙石数据总经理练海荣获评CCSA TC601 2024年度突出贡献专家
- 6 荣誉奖项 智库生态丨龙石数据练海荣、孙晓宁受聘中国信通院政务大数据方向智库专家
- 7 公司动态 龙石数据在DAMA数据管理峰会再次分享数据要素价值运营和第三方数据质量管理
- 8 公司动态 江阴市数据局莅临龙石数据调研
- 9 公司动态 【技能提升】SQL进阶脚本,专业技能再提升,服务再升级
- 10 数据集成 龙石数据集成平台有哪些要点?
