数据中台项目测试实践
2021-12-19 20:37 浏览量:559
背景介绍
某知名车企(FT)数字化转型的战略目标是构筑百万辆的数字化智网基盘,促进公司业绩增长。
提供客户更好的服务体验
打造更智能的企业运营
实现数据驱动的业务创新
打造三端合一:统一平台,统一数据,统一运营,直达客户,运营客户。
FT数据中台的交付内容有很多,这里暂先列举:数据仓库构建、标签与指标开发。
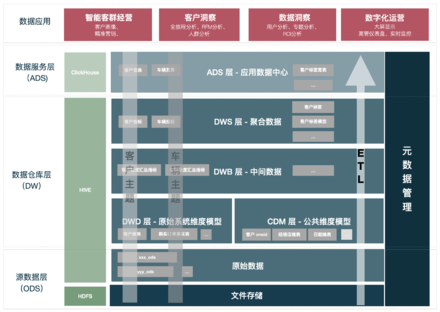
某知名车企数据中台的数据分层(如下图)共分为:
数据应用 指标的可视化展示、进行目标人员人群圈选、客户画像展示等。
数据服务层(ADS) 对维度进行汇总计算, 服务层数据生成。
数据仓库层(DW)
(1)DWS聚合层 - 根据主题模型,计算指标、标签等。
(2)DWB中间层 - 存储在计算聚合层数据时的基础数据或高复用的中间数据。
(3)CDM公共维度模型层 - 构建一致性维度模型
(4)DWD原系统维度模型层 - 构建原始系统维度模型(异常值清洗、统一名、维度转换)
源数据层(ODS) 抽取业务系统源数据
测试实践
对于FT这类的数据中台,接入业务系统较多、数据量大、数据多样,从ODS源数据层到ADS的数据服务层,整个数据处理通道长、计算逻辑复杂。6个月接入5个业务系统数据、交付上百个指标和标签,如何保证这么多的指标和标签按时高质量交付,这对整个团队提出了非常高的要求。
高质量的团队旨在开发全生命周期中,践行【提前预防、及时纠错】。
项目上构建测试实践活动时,依据整个开发实践全生命周期,从最初的故事场景编写,到故事验收上线,全流程参与。早测试早反馈,早发现早纠错。
具体项目质量相关实践活动见如下图所示,旨在保证高质量产出。
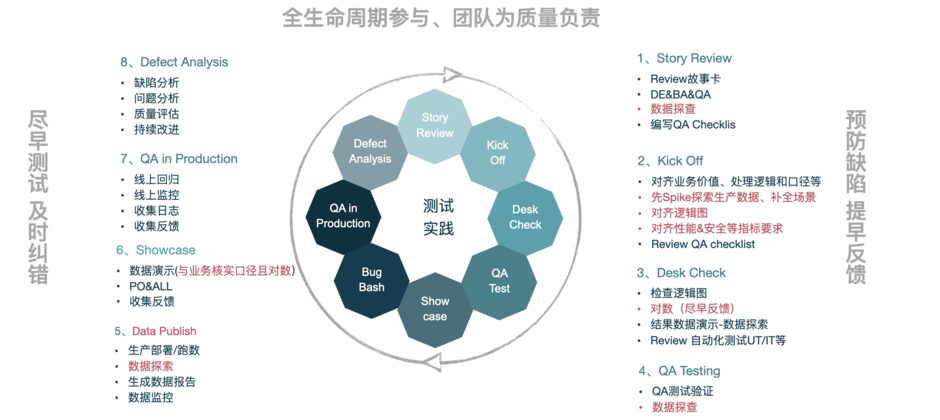
以上测试实践活动是大家熟悉的敏捷QA实践,讲过很多次了,具体细节不再过多赘述(详见:《机器学习平台测试篇》的QA实践章节)。
可能细心的你已发现,有些测试实践被醒目的粉色字体高亮。以上粉色字体就是专为此类项目(数据中台、数据仓库等)制定的特别的测试实践活动。
数据探索
为什么要进行数据探索?
真实数据中,存在各种意想不到的用例或异常数据,经过数据探索,更加了解数据,完善大家对数据的认识,避免由于不了解数据遗漏场景或从而造成的Bug。对结果表进行数据探索,是为了盘查一遍最终交付数据是否有异常或不符合预期认认知的结果。
数据探索做什么?
检查输入表与结果出表有没有全null或末知,有没有字段与value不匹配。(特别是不符合预期的数据情况)
检查关键字段(逻辑计算要使用的字段)的字段类型是否预期
检查关键字段(逻辑计算要使用的字段)的value中,有没有出现不符合实际情况的值。
统计结果表中关键字段,数据分布是否符合预期认知。
统计结果表的数据量与预期是否一致。
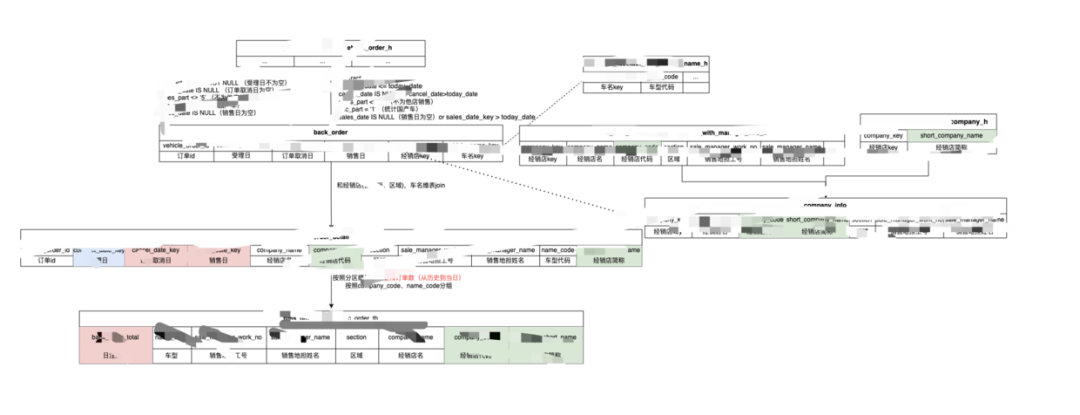
逻辑图
各类指标与标签的业务口径与技术口径较为复杂,一个指标计算,可能关联多张表,涉及到的关键字段计算也较多。为了更直观高效的对齐BA + DE + QA理解,用唯一的逻辑图来展示,呈现计算涉及到的关键表、关键字段、逻辑关系和预期结果,以快速达成一致理解。
逻辑图不仅能以更直观的方式辅助团队快速达成一致理解,同时,也可以帮助工程师快速完成开发,逻辑图转换成SQL代码更高效。
对数
做过指标开发的都知道,开发指标一定要提前对数 (与业务方核对指标结果数据)。
当依据BA和PO确定的指标口径完成开发后,计算出来的指标结果很可能不符真实预期,为什么?
(1)可能由于对业务口径理解翻译后的技术口径不准确,导致指标结果符合真实预期。
(2)PO或业务人员可能遗漏某类场景,导致指标结果不符合真实预期。
(3)由于某类特殊问题或Bug,导致指标结果不符合真实预期。
介于以上可能存在的风险,业务方相关指标结果数据时,团队会提前进行对数,越早越好,提前发现大的差异,可尽早调整或修正。有的时候,结果数据对不上有各种原因,在查找原因的过程中,极其耗时耗力。
那么,数据遇到对不上的情况如何处理、何时停止?
与客户提前确定可接纳误差
对于如此体量的数据计算,不论是在异常数据的处理差异或特殊边界处理的差异,都可能导致数据结果无法完全核对上。但,如果为了追求100%的准确,可能付出的成本越越大于其带来的价值。因此,数据团队一定要明白,大数据下追求100%准确的代价。
误差占比整理出来
对于误差较大的,优先与业务侧核对技术口径,以查明原因。
对于误差较小的,在客户接纳范围停止核实误差。
数据对不上,及时找BA表明情况,由BA及时与PO沟通获取反馈。
Data Publish
数据中台或数仓项目中,生产数据体量及其大,而且生产环境上的全量数据可能存在我们预想不到的惊喜或惊吓,所以,在上线之后,一定要及时进行数据检查验证。
生产数据结果进行数据探索
具体内容参见【数据探索】小节中的Checklist;除了全分区检查(历史分区、最新分区、分区总数)、计算结果分布检查、脱敏字段检查、性能检查等。
数据监控检验
确保发布的数据表已增加监控告警 确保已增加主键唯一性监控 确咻已增加数据量监控等

Review测试(分层验证)
数据类项目的自动化测试一定要注意,分层验证。
从ODS - > DWD -> DWB - > DM -> ADS每一层各自测试验证自己的处理逻辑。
测试方式就是构造上游测试数据与预期结果数据,比对程序输出与提前准确的预期数据。
例如:验证DWD表的结果,先用excel把ODS层用到的Input表中可能出现的数据场景进行构造;然后,再用excel把期望DWD层预期的输出Output表构造;最后,运行程序代码后,对比实际输出和预期构建的Output表。
提效手段
以上的测试实践活动,帮助团队把控质量,即"保质"。其实,测试增加,必然拉低整体速率。那么,如何使的团队不降质量标准的前提下,高效开发与测试?即"保质"的同时还要"保量"?
避免返工
前面介绍敏捷QA实践活动为得就是尽早参与、提前发现问题、预防缺陷,避免返工,从而达到高效开发。
工具代替人工(即自动化代替手动)
在项目中,开发人员的数据建模处理、指标开发、指标管理应用发布、标签API发布、数据监控,这些功能都是由工具自动生成代码,完成开发的。大大节约了项目时间,提高了开发速度。
特别提一下EXCEL自动化测试工具,可以用一页EXCEL即可完成所有的数据测试用例的构造。大家都知道数据项目构建数据集是一个费时费力的活儿。有了这个EXCEL编写测试数据的工具,团队大大节约了时间。

提高复用、减少重复
项目开发过程中,相同的代码逻辑抽取 公共片断或者 合理分层(输出中间表),这样避免相同的业务逻辑开发重复和重复测试。比如:同类指标的维度计算都是相同的,抽取了公共的维度代码片断,针对公共代码片断进行了测试验证,即使之后业务有变动,修改一处代码即可。
精准抽样
构建测试数据时,精准抽样测试。一条测试数据精准覆盖一个逻辑,避免重复用例的构造。在Review UT时,经常发现有重复场景,会提醒大家及时删除重复用例。多余的用例没有价值反而还会造成干扰至少随时用例的增多,运行速度也会影响。
数据报告
通过data filling生成数据报告,大多数据探索Checklist的结果通过数据报告即可拿到,减少人工探索的成本。
项目尝试的各项实践活动、以及提炼的各种工具非常多,感兴趣的线下联系了解细节,由于篇幅原因,此文便不展开太多。
来源:春晨的一缕曙光
- 分享:
热门文章
- 1 AI+大数据 4个关键点:让数据治理变得简单、高效
- 2 AI+大数据 AI与数据的双向奔“赋”
- 3 荣誉奖项 【喜报】龙石数据成功入选苏州市数据创新应用实验室
- 4 数据中台 龙石数据中台V3.5.2升级 | 新增码表转换功能
- 5 荣誉奖项 龙石数据总经理练海荣获评CCSA TC601 2024年度突出贡献专家
- 6 荣誉奖项 智库生态丨龙石数据练海荣、孙晓宁受聘中国信通院政务大数据方向智库专家
- 7 公司动态 龙石数据在DAMA数据管理峰会再次分享数据要素价值运营和第三方数据质量管理
- 8 公司动态 江阴市数据局莅临龙石数据调研
- 9 公司动态 【技能提升】SQL进阶脚本,专业技能再提升,服务再升级
- 10 数据集成 龙石数据集成平台有哪些要点?
