数据治理方案技术调研 Atlas VS Datahub VS Amundsen
2021-04-28 07:30 浏览量:733
数据治理意义重大,传统的数据治理采用文档的形式进行管理,已经无法满足大数据下的数据治理需要。而适合于Hadoop大数据生态体系的数据治理就非常的重要了。
大数据下的数据治理作为很多企业的一个巨大的难题,能找到的数据的解决方案并不多,但是好在近几年,很多公司已经进行了尝试并开源了出来,本文将详细分析这些数据发现平台,在国外已经有了十几种的实现方案。
数据发现平台可以解决的问题
为什么需要一个数据发现平台?
在数据治理过程中,经常会遇到这些问题:数据都存在哪?该如何使用这些数据?数据是做什么的?数据是如何创建的?数据是如何更新的?
。。。。。
数据发现平台的目的就是为了解决上面的问题,帮助更好的查找,理解和使用数据。
比如Facebook的Nemo就使用了全文检索技术,这样可以快速的搜索到目标数据。
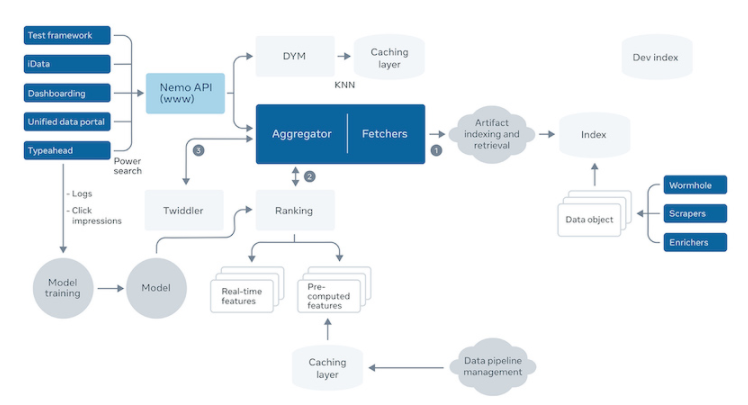
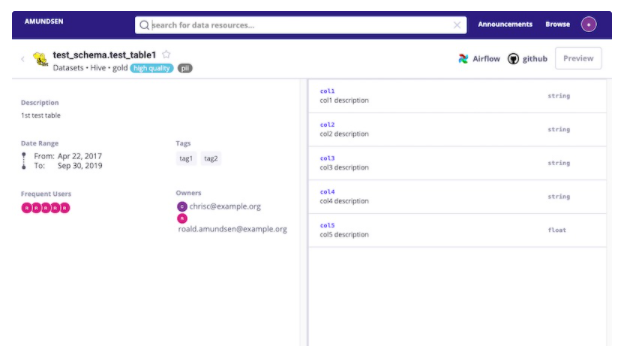
用户浏览数据表时,如何快速的理解数据?一般的方式是把列名,数据类型,描述显示出来,如果用户有权限,还可以预览数据。
下面是Amundsen的数据列展示功能。
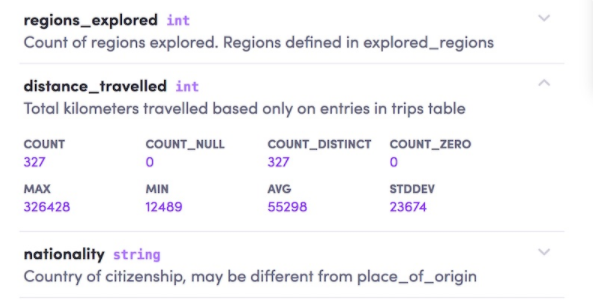
数据ETL是一个大问题,特别是如何把这些展示出来更是非常难,其实数据的ETL是可以用数据的流向图表示的,很多平台都支持这种功能,比如 Databook,还有Metcat。
Amundsen就和数据调度平台Airflow有着非常好的结合。
数据发现平台对比
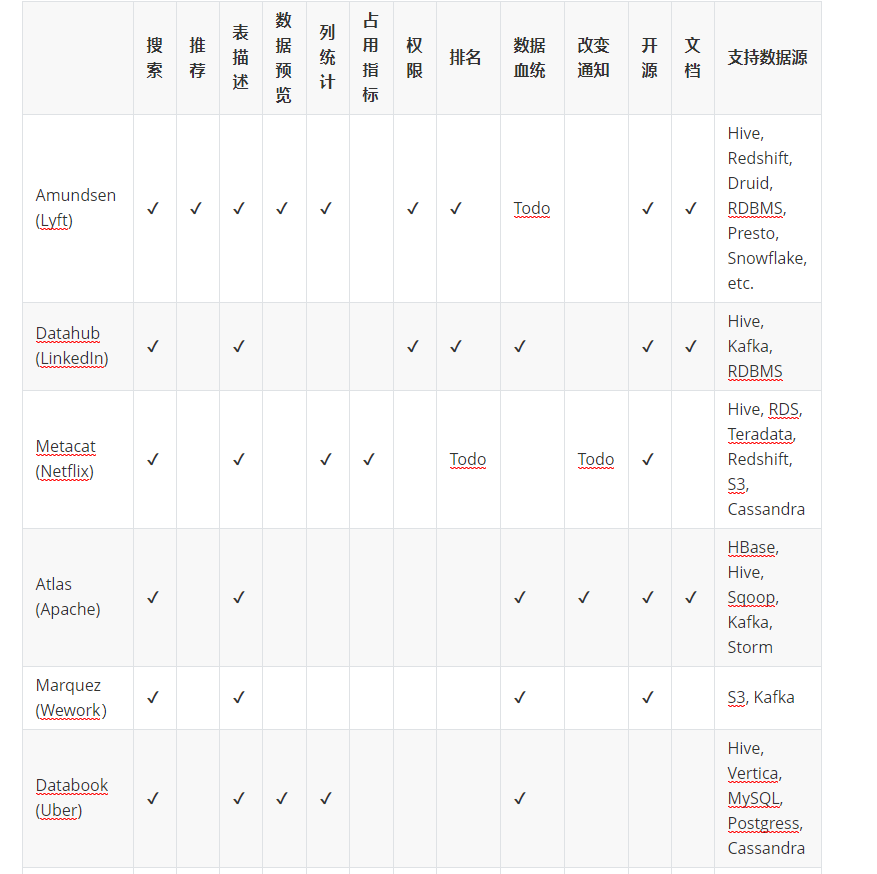
下面一张表 对比一下各大平台对于上述功能的支持情况
| 搜索 | 推荐 | 表描述 | 数据预览 | 列统计 | 占用指标 | 权限 | 排名 | 数据血统 | 改变通知 | 开源 | 文档 | 支持数据源 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Amundsen (Lyft) | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | Todo | ✔ | ✔ | Hive, Redshift, Druid, RDBMS, Presto, Snowflake, etc. | ||
| Datahub (LinkedIn) | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | Hive, Kafka, RDBMS | |||||
| Metacat (Netflix) | ✔ | ✔ | ✔ | ✔ | Todo | Todo | ✔ | Hive, RDS, Teradata, Redshift, S3, Cassandra | |||||
| Atlas (Apache) | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | HBase, Hive, Sqoop, Kafka, Storm | ||||||
| Marquez (Wework) | ✔ | ✔ | ✔ | ✔ | S3, Kafka | ||||||||
| Databook (Uber) | ✔ | ✔ | ✔ | ✔ | ✔ | Hive, Vertica, MySQL, Postgress, Cassandra | |||||||
| Dataportal (Airbnb) | ✔ | ✔ | ✔ | ✔ | ✔ | Unknown | |||||||
| Data Access Layer (Twitter) | ✔ | ✔ | ✔ | HDFS, Vertica, MySQL | |||||||||
| Lexikon (Spotify) | ✔ | ✔ | ✔ | ✔ | ✔ | Unknown |
这里介绍一下五个开源的解决方案
DataHub (LinkedIn)
LinkedIn开源出来的,原来叫做WhereHows 。经过一段时间的发展datahub于2020年2月在Github开源
https://github.com/linkedin/datahub
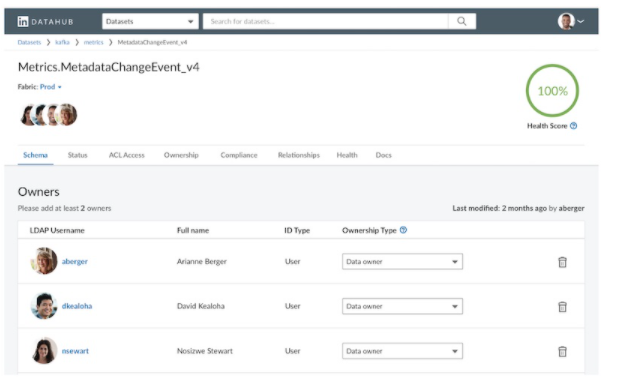
可以说是一个非常充满活力的项目,有着表结构,搜索,数据血统等功能,还有用户和组等功能。
官方也提供了文档。开源版本支持Hive,Kafka和关系数据库中的元数据。
所以Datahub的使用率还是非常高的。
Amundsen (Lyft)
Lyft 于2019年4月开发了Amundsen,并与10月开源。
https://github.com/amundsen-io/amundsen
Amundsen提供了搜索与排名的功能,帮助更好的查找数据表。
支持的数据源非常丰富,支持hive ,druid等超过15个数据源,而且还提供与任务调度airflow的融合,并提供了与superset等BI工具的集成方式。
而数据血统的功能也正在开发之中。
Metacat(Netflix)
Netflix在2018年6月开源了Metacat。
Metacat支持Hive,Teradata,Redshift,S3,Cassandra和RDS的集成。
不过虽然Metacat开源,但是官方没有提供文档,资料也很少。
Marquez (WeWork)
Wework于2018年10月开源了Marquez
Marquez也对Airflow有着很好的支持。
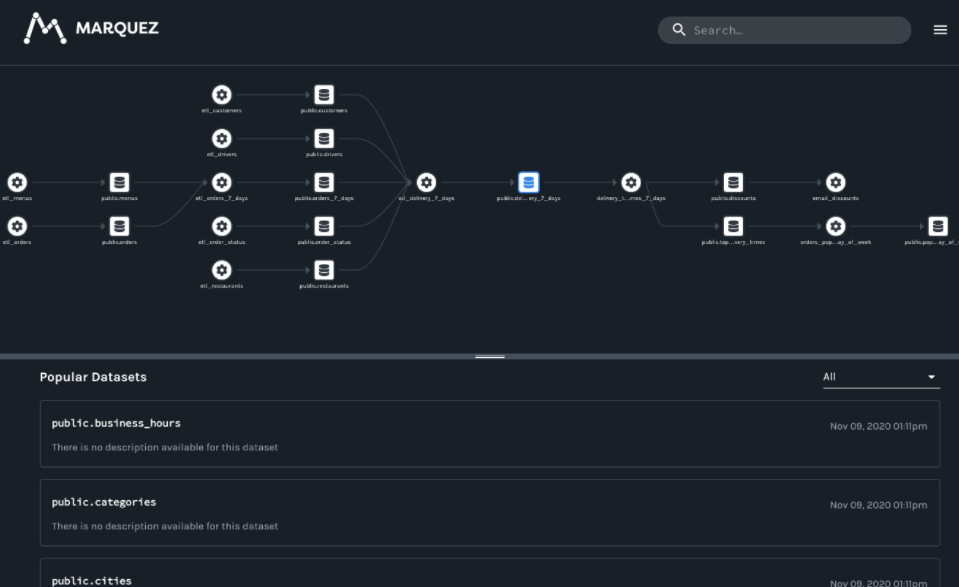
可以看到Marquez还在持续的更新中,保持关注。
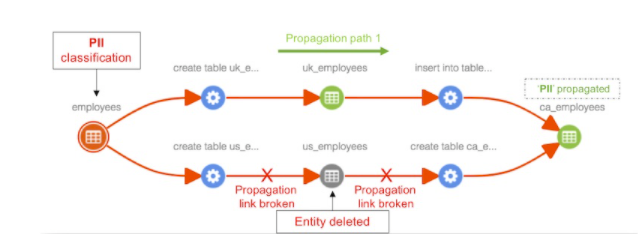
Apache Atlas(Hortonworks)
作为数据治理计划的一部分,Atlas于2015年7月开始在Hortonworks进行孵化。
Atlas 1.0于2018年6月发布,当前版本是2.1。
Atlas的主要目标是数据治理,支持与HBase,Hive和Kafka的集成。
github地址
https://github.com/apache/atlas
丰富的文档

如何选择
首先说一下笔者的选择,虽然对datahub和amundsen非常的感兴趣,最后还是选择了Atlas。
开源,文档的丰富程度,功能,这些在上文表格中都做了详细的对比,如何选择还是要考虑实际情况。
开源的有五家:Amundsen Datahub Metacat Marquez Atlas
有文档的有三家:Amundsen Datahub Atlas
搜索功能较强 :Amundsen
有数据血统功能:Datahub Atlas
考虑到项目的周期,实施性等情况,还是建议大家从Atlas入门,打开数据治理的探索之路。
当然也有公司同时采用了Atlas和Amundsen,Atlas处理元数据管理,利用Amundsen强大的数据搜索能力来做数据搜索,这也是一种不错的选择。
来源:数据社
- 分享:
热门文章
- 1 AI+大数据 4个关键点:让数据治理变得简单、高效
- 2 AI+大数据 AI与数据的双向奔“赋”
- 3 荣誉奖项 【喜报】龙石数据成功入选苏州市数据创新应用实验室
- 4 数据中台 龙石数据中台V3.5.2升级 | 新增码表转换功能
- 5 荣誉奖项 龙石数据总经理练海荣获评CCSA TC601 2024年度突出贡献专家
- 6 荣誉奖项 智库生态丨龙石数据练海荣、孙晓宁受聘中国信通院政务大数据方向智库专家
- 7 公司动态 龙石数据在DAMA数据管理峰会再次分享数据要素价值运营和第三方数据质量管理
- 8 公司动态 江阴市数据局莅临龙石数据调研
- 9 公司动态 【技能提升】SQL进阶脚本,专业技能再提升,服务再升级
- 10 数据集成 龙石数据集成平台有哪些要点?
