元数据:数据治理的基石
2020-06-10 08:00 浏览量:497
背景
据说,英语中元数据meta一词最早出现于1968年,其是对希腊语前缀"meta-"的粗略翻译,用于表明更抽象层次的事物。尽管元数据一词只有几十年的历史,然而几千年的图书馆管理员们一直在工作中使用着元数据,只不过我们先所谓的“元数据”是历史上被称为"图书馆目录信息"。图书目录中的信息解决了一个十分关键的问题,就是如何帮助用户在图书馆快速地、准确地找到想要的资料。

图为爱尔兰最古老的都柏林圣三一学院图书馆
图书目录中依然延续至今的信息片段:书名、作者或整理、主题、简介和篇幅。但如今其含有更多的信息,如出版社、出版时间、定价、条形码和上架建议等等。

如今的图书目录采用更多的信息片段。每本著作都有唯一的编码号码(图书馆的书一般带有手写或机打标签),根据某种编码方案(如杜威十进制分类法等)设计的纯数字或字母数字混编字符串,来帮助图书馆用户在书架上准确地快速地找到著作。
试想几种场景,一个藏有几千万册的图书馆没有分类编码存储;著作没有著作名称、作者、简介等;著作封面简介与内容不符;著作没有目录等等。就会出现这样的结果:
图书馆无法管理的自己图书,很难统计馆内多少图书、每类图书多少
图书馆无法根据大众读者喜好摆放某类图书的位置
读者无法找到自己想读的图书
读者费时费力地找到了图书,但内容与描述不符
读者精疲力尽地找到了图书,但无法快速定位到某些章节
读者心平气和地找到了图书,但内容是错误的
读者心满意足地找到了图书,但内容是下册的,又必须从上册读起
读者喜出望外地找到了图书,但内容是用甲骨文写的,用梵文作的注解(读者看不懂)
读者欲哭无泪地找到了图书,但图书馆要下班关门了
......读者崩溃了.....
同样道理,若企业没有做好元数据管理,那么数据消费者或数据分析师会面临上述读者的同类困境:找不到数据、找到没有上下文无法理解数据、理解了数据因数据格式无法使用、内容有误导致结果错误、查询性能低、数据加工好已经错过时效等等问题。解决上述困境或管好这些对事物的描述信息都属于元数据管理的概念范畴。
如果没有元数据管理,数据无法被有效地组织起来、被准确地理解、被合理地使用和产出预期的结果,那么数据价值无法发挥出来,于是数据变成了数据负债;如果没有元数据,那么数据的内容和真实性就难以估量,继而可能造成数据价值和可用性的降低。元数据是发挥数据价值的前提,是数据治理的基石。
何为元数据
“元数据是关于数据的数据”(准确地说这个定义不大实用,且不易被理解)。从数据、信息、知识和智慧人类认知领域的层次结构来讲,数据是通过工具或机器搜集的原始资料。确切地说,数据是原始、未经处理的资料或潜在信息。信息就是经过某种处理并供人使用的数据。知识指的是你知道的事情,也就是经过内化的信息,而智慧则是指了解如何运用知识。元数据是对潜在信息的信息,是关于数据的更高层次抽象,是对数据的描述。
准确的元数据是必不可少的,也是迅速有效地对数据去粗取精的关键。没有元数据,数据就毫无意义,只不过是一堆数字或文字而已。
元数据只是发挥数据价值的充分条件,“酒香也怕巷子深”如制定了合理并严格执行数据标准,通用的易用的模型设计数仓底座,极高的良性循环的数据质量,安全的顺滑的数据访问和数据共享机制和合理的高效的管理流程等,就亟须统一标准的、合理的、易用理解的、易用使用的元数据管理系统,不能把“好酒”(数据)埋没掉,要把数据宣传出去,让更多用户知晓、理解和高效使用,并使数据价值得最大发挥。
同时也应避免言过其实的“金玉其外,败絮其中”即数据不标准、数据质量较差、数据存在异常和形散而神散、重复建设及计算的数仓等等,即使有个华丽的元数据可视化展示,只会换来业务用户更多抱怨。
总之,名副其实是最好的,数据与元数据同步持续良性迭代优化。
元数据应用领域较广,种类甚多, 按照不同应用领域或功能,元数据分类有很多种方法或种类,元数据一般大致可为三类:业务元数据、技术元数据和操作元数据。各自包含内容如下:
业务元数据:
指标名称、计算口径、业务术语解释、衍生指标等
数据概念模型和逻辑模型
业务规则引擎的规则、数据质量检测规则、数据挖掘算法等
数据血缘和影响分析
数据的安全或敏感级别等
技术元数据:
物理数据库表名称、列名称、列属性、备注、约束信息等
数据存储类型、位置、数据存储文件格式或数据压缩类型等
数据访问权限、组和角色
字段级血缘关系、ETL抽取加载转换信息
调度依赖关系、进度和数据更新频率
操作元数据:
系统执行日志
访问模式、访问频率和执行时间
程序名称和描述
版本维护等
备份、归档时间、归档存储信息
上述只是大致的分为三类,简单地列举常用的元数据信息,其实还包括结构性元数据、保存性和权限元数据等等这里就不一一列举了。
元数据管理
元数据也是数据,同样适用数据生命周期管理。元数据生命周期可分为采集、整合、存储、分析、应用、价值和服务几个阶段。
元数据架构
元数据战略是关于企业元数据管理目标的说明,也是开发团队的参考框架。元数据战略决定了企业元数据架构。元数据架构可分为三类:集中式元数据架构、分布式元数据架构和混合元数据架构。
集中式元数据架构:
集中式架构包括一个集中的元数据存储,在这里保存了来自各个元数据来源的元数据最新副本。保证了其独立于源系统的元数据高可用性;加强了元数据存储的统一性和一致性;通过结构化、标准化元数据及其附件的元数据信息,提升了元数据数据质量。集中式元数据架构有利于元数据标准化统一管理与应用。
分布式元数据架构:
分布式架构包括一个完整的分布式系统架构只维护一个单一访问点,元数据获取引擎响应用户的需求,从元数据来源系统实时获取元数据,而不存在统一集中元数据存储。虽然此架构保证了元数据始终是最新且有效的,但是源系统的元数据没有经过标准化或附加元数据的整合,且查询能力直接受限于相关元数据来源系统的可用性。
混合式元数据架构:
这是一种折中的架构方案,元数据依然从元数据来源系统进入存储库。但是存储库的设计只考虑用户增加的元数据、高度标准化的元数据以及手工获取的元数据。
这三类各有千秋,但为了更好发挥数据价值,就需要对元数据标准化、集中整合化、统一化管理。如果企业做功能较为完善的数据资产管理平台可采用集中式元数据架构。
元数据生命周期
笔者这里以集中式元数据架构为例讲解,通过对数据源系统的元数据信息采集,发送Kafka消息系统进行解耦合,再使用Antlr4开发各版SQL解析器,对元数据信息新增、修改和删除操作进行标准化集中整合存储。在元数据集中存储的基础上或过程中,可提供元数据服务与应用,如数据资产目录、数据地图、集成IDE、统一SQL多处理引擎、字段级血缘关系、影响度分析、下线分析、版本管理和数据价值分析等(这些元数据应用可根据产品经理设计理念进行优化组合,笔者这里拉平排列各功能应用,为了方便讲解各元数据应用模块)。这里就包括了元数据采集、整合、存储、分析、应用等阶段的生命周期。
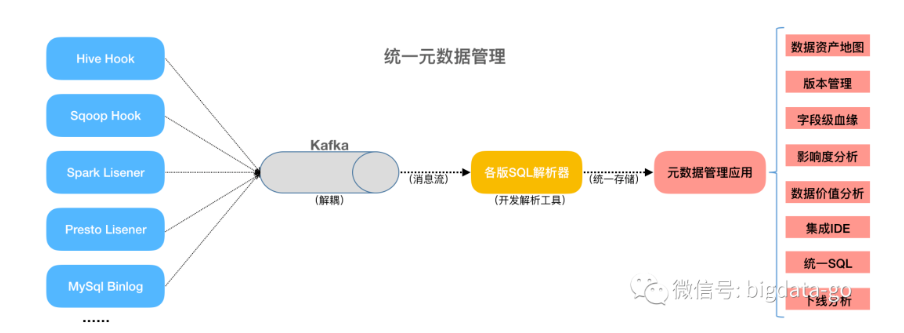
元数据管理与常见元数据应用:
数据资产地图
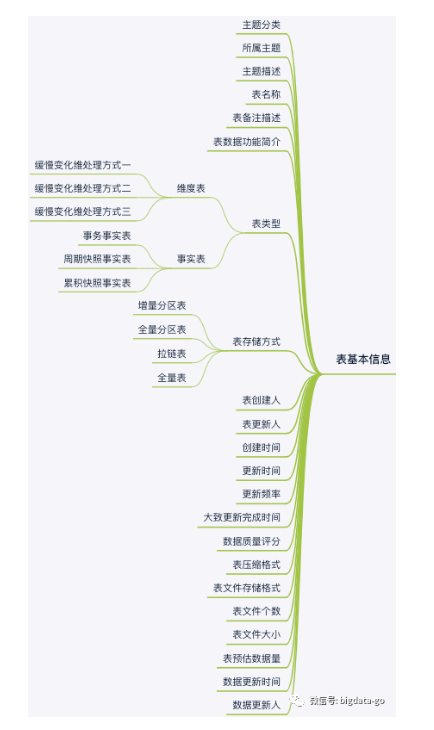
数据资产地图包括数据资产目录和血缘关系等。通过对元数据的标准化、加工整合形成数据资产地图。数据资产地图一般可支持全文搜索和模糊查询表信息检索、也支持按照关系查找或按主题域层级查找。一般采集Elasticsearch做元数据信息检索和Neo4J做血缘关系的数据地图。如图:

检索表的元数据信息包括分层信息、分层数据库数量、每层功能描述、数据库表数量、总计存储大小、存储类型、实际表存储位置,表基本信息包括主题分类、所属主题、主题描述、表名称、表数据功能简介、表类型、表创建人、表更新人、创建时间、更新时间、数据更新人、数据更新时间、表预估数据量、表文件大小、表文件个数、表文件存储格式、表压缩格式、数据质量评分、数据热度、更新频率、大致更新完成时间等等。
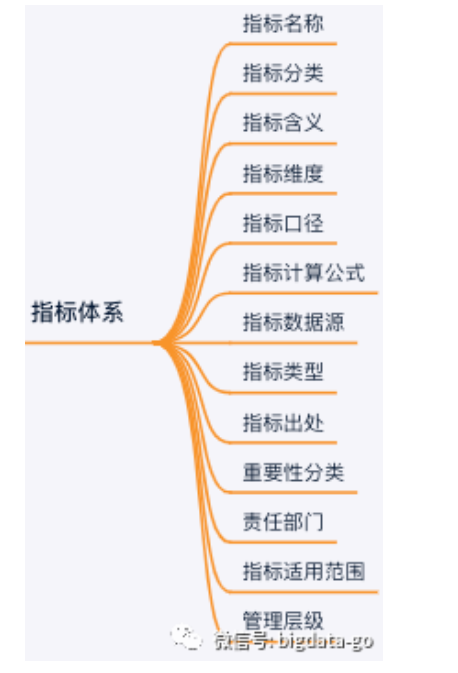
还包含指标业务元数据信息如下:
元数据信息也要包括归档和已销毁的数据记录的元数据信息。归档元数据信息便于数据分析师查找,快速恢复,重新使用挖掘出数据价值。已销毁元数据信息便于数据安全管理。
还包括未采集数据资产管理平台的元数据信息,实际数据还分布在各个源系统的数据,需要抽取、转换、清洗和加载到数据平台的相关流程和ETL工具,便于业务用户元数据查找和数据使用。
版本管理
元数据版本管理功能,可对元数据进行发布、查看历史版本、导出历史版本和版本对比操作。在元数据未发布或未正式上线使用时,其他仅有使用权限的用户无法查看此版本信息,这样保证了元数据系统权威性和可靠性。这里同样涉及影响度分析和下线分析元数据应用模块,如表结构变更、删除等下游系统都能做到动态感知提醒或告警功能,下线分析也是如此。
血缘关系
血缘关系包含了集群血缘关系、系统血缘关系、表级血缘关系和字段血缘关系,其指向数据的上游来源,向上游追根溯源。这里指的血缘关系一般是指表级和字段级,其能清晰展现数据加工处理逻辑脉络,快速定位数据异常字段影响范围,准确圈定最小范围数据回溯,降低了理解数据和解决数据问题的成本。
在传统的ETL工具如Informatica、DataStage和开源Kettle中都有相应血缘关系,以informatica ETL工具的表级血缘关系和字段级血缘举例,如图:
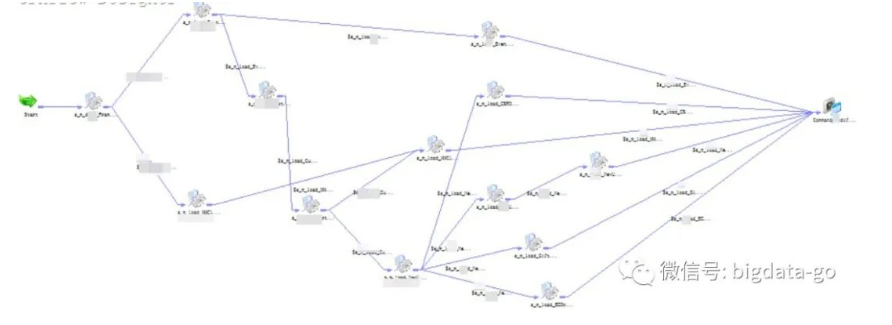
(上图:表级血缘关系)
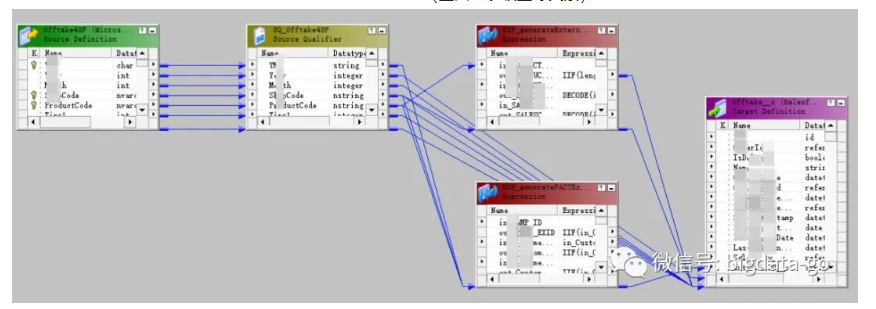
(上图:字段级血缘关系,也称mapping)
但只能展现使用这些传统ETL工具的血缘关系,其他方式ETL却无法生成血缘关系。其不灵活也不便于元数据统一集中管理。
大数据时代,大部分企业数据仓库都使用Hive作为数仓存储和ETL数据加工,如果是单一Hive处理引擎,可使用Hive Hook直接解析字段级血缘关系和表级别血缘关系。如果多种计算引擎就使用上述笔者给出技术架构图,通过对不同存储和计算引擎监听动作,使用Antlr4开发各版本SQL解析工具,动态识别元数据信息变更、删除和新增实时或准实时生成集群血缘关系、系统血缘关系、表级血缘关系和字段血缘关系。通过从语法树遍历解析后存储Neo4j图数据

影响度分析
影响度分析,也是较为血缘关系应用的一部分,其用来分析数据的下游流向。当系统进行升级改造时,能动态数据结构变更、删除及时告知下游系统。通过依赖数据的影响性分析,可以快速定位出元数据修改会影响到哪些下游系统,哪些表和哪些字段。从而减少系统升级改造带来的风险。
下线分析
下线分析和影响度分析功能大致相同,只是应用的侧重点不同,下线分析是根据数据热度,对冷数据或冰数据归档下线时,是否对其他应用造成依赖影响,便于数据归档操作。
数据价值分析
数据价值分析主要是对数据表的被使用情况进行统计,价值密度、访问频次、使用方式、时效性等级等维度评估,从而评级出数据热度,热数据、温数据、冷数据和冰数据。数据价值访问评估一些常用的维度:表的访问频率分析、表分区数据访问分析、跨表访问分析、跨层访问分析、跨库访问分析、字段访问频率分析、表访问用户量分析和分层表访问总量分析等。数据热度应随着时间的推移,数据价值会变化,应动态更新数据热度等级,推动数据从产生到销毁数据生命周期管理。总之,在成本可控、可量化、可管理的前提下,从数据中挖掘出更多有效的数据价值。
集成IDE
为了方便数据提供者或数据分析师数据收集、清洗、加工数据的方式不同,集成IDE集成了不同数据开发语言或工具,如集成Python、R、Shell和各版本数据处理引擎的SQL。这是统一的数据开发加工入口。每个元数据应用模块都不是独立的,需要其他元数据应用模块如数据资产地图和数据目录集成,便于快速定位分析师要查找的数据和准确地理解数据,从而提高了数据加工或数据分析的效率。
统一SQL路由引擎
集成IDE开发中提到统一SQL路由引擎,其统一使用HQL语言智能地路由多种执行引擎。这降低了用户熟悉其他SQL的学习成本,其可屏蔽了多种引擎SQL差异,可基于SQL复杂度和成本估算、优先级和各引擎集群空闲程度,把用户提交的SQL路由到合适的执行引擎,如果Hive转换Presto、Spark或其他引擎执行失败,则使用Hive引擎来补救执行,最终都会返回结果。统一SQL路由引擎是使用Antlr4实现的词法文件,具体实现可参考笔者之前的文章,这里给出链接如下:
元数据应用还有很多,如数据探查、元数据对比分析是否存储重复计算和重复存储等等,限于篇幅,不一一列举。
总结
如何从数据中探索信息、发现知识,寻找隐藏在数据中的趋势、模式、相关性及隐含规律,都要我们用于更好的数据洞察力,而这种洞察力的基础来自我们对元数据的理解。
元数据是用数据管理数据,是快速查找数据、精确定位数据、准确地理解数据和快速使用数据的关键。元数据管理还须符合数据标准、较高的数据质量、数据安全、数据共享、合理顺滑管理流程。在存储、计算和人力成本合理可控、可管理的前提下,使数据价值得最大发挥,是数据全生命周期管理重要组成部分。是提升数据价值发挥的前提,是数据治理的基石。
来源:BigDataplus
作者:后羿BigDataplus
- 分享:
热门文章
- 1 数据中台 龙石数据中台V3.5.2升级 | 新增码表转换功能
- 2 荣誉奖项 龙石数据总经理练海荣获评CCSA TC601 2024年度突出贡献专家
- 3 荣誉奖项 智库生态丨龙石数据练海荣、孙晓宁受聘中国信通院政务大数据方向智库专家
- 4 公司动态 龙石数据在DAMA数据管理峰会再次分享数据要素价值运营和第三方数据质量管理
- 5 公司动态 江阴市数据局莅临龙石数据调研
- 6 公司动态 【技能提升】SQL进阶脚本,专业技能再提升,服务再升级
- 7 数据集成 龙石数据集成平台有哪些要点?
- 8 数据中台 数据中台选型应注意哪些事项?
- 9 数据中台 龙石数据中台有哪些功能和特点?
- 10 数据中台 数据中台(大数据平台)之数据资源目录
